2022

Reconstructing Expressive 3D Humans from RGB Images
2021
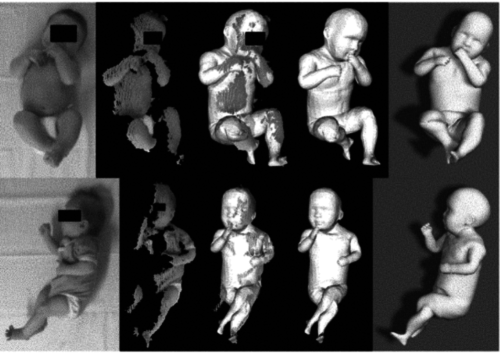
Skinned multi-infant linear body model
Hesse, N., Pujades, S., Romero, J., Black, M.
(US Patent 11,127,163, 2021), September 2021 (patent)
2020
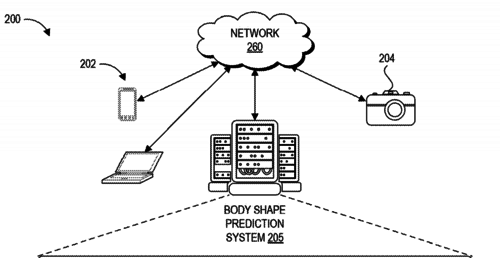
Machine learning systems and methods of estimating body shape from images
Black, M., Rachlin, E., Heron, N., Loper, M., Weiss, A., Hu, K., Hinkle, T., Kristiansen, M.
(US Patent 10,679,046), June 2020 (patent)
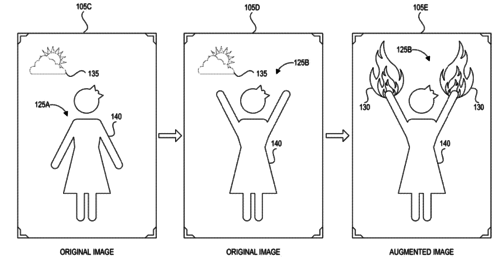
Machine learning systems and methods for augmenting images
Black, M., Rachlin, E., Lee, E., Heron, N., Loper, M., Weiss, A., Smith, D.
(US Patent 10,529,137 B1), January 2020 (patent)
2019

Towards Geometric Understanding of Motion
The motion of the world is inherently dependent on the spatial structure of the world and its geometry. Therefore, classical optical flow methods try to model this geometry to solve for the motion. However, recent deep learning methods take a completely different approach. They try to predict optical flow by learning from labelled data. Although deep networks have shown state-of-the-art performance on classification problems in computer vision, they have not been as effective in solving optical flow. The key reason is that deep learning methods do not explicitly model the structure of the world in a neural network, and instead expect the network to learn about the structure from data. We hypothesize that it is difficult for a network to learn about motion without any constraint on the structure of the world. Therefore, we explore several approaches to explicitly model the geometry of the world and its spatial structure in deep neural networks.
The spatial structure in images can be captured by representing it at multiple scales. To represent multiple scales of images in deep neural nets, we introduce a Spatial Pyramid Network (SpyNet). Such a network can leverage global information for estimating large motions and local information for estimating small motions. We show that SpyNet significantly improves over previous optical flow networks while also being the smallest and fastest neural network for motion estimation. SPyNet achieves a 97% reduction in model parameters over previous methods and is more accurate.
The spatial structure of the world extends to people and their motion. Humans have a very well-defined structure, and this information is useful in estimating optical flow for humans. To leverage this information, we create a synthetic dataset for human optical flow using a statistical human body model and motion capture sequences. We use this dataset to train deep networks and see significant improvement in the ability of the networks to estimate human optical flow.
The structure and geometry of the world affects the motion. Therefore, learning about the structure of the scene together with the motion can benefit both problems. To facilitate this, we introduce Competitive Collaboration, where several neural networks are constrained by geometry and can jointly learn about structure and motion in the scene without any labels. To this end, we show that jointly learning single view depth prediction, camera motion, optical flow and motion segmentation using Competitive Collaboration achieves state-of-the-art results among unsupervised approaches.
Our findings provide support for our hypothesis that explicit constraints on structure and geometry of the world lead to better methods for motion estimation.
Method for providing a three dimensional body model
Loper, M., Mahmood, N., Black, M.
September 2019, U.S.~Patent 10,417,818 (patent)
2018

Model-based Optical Flow: Layers, Learning, and Geometry
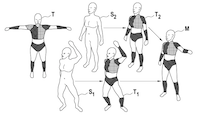
Co-Registration – Simultaneous Alignment and Modeling of Articulated 3D Shapes
Black, M., Hirshberg, D., Loper, M., Rachlin, E., Weiss, A.
February 2018, U.S.~Patent 9,898,848 (patent)

Combining Data-Driven 2D and 3D Human Appearance Models
2017
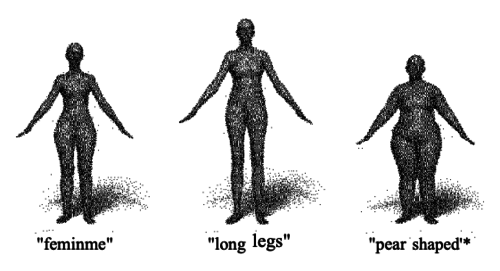
Crowdshaping Realistic 3D Avatars with Words
Streuber, S., Ramirez, M. Q., Black, M., Zuffi, S., O’Toole, A., Hill, M. Q., Hahn, C. A.
August 2017, Application PCT/EP2017/051954 (patent)

Human Shape Estimation using Statistical Body Models
Learning Inference Models for Computer Vision

Capturing Hand-Object Interaction and Reconstruction of Manipulated Objects
2016
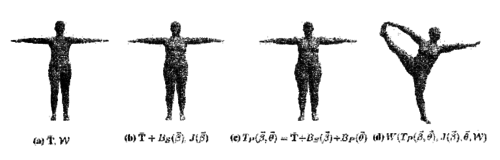
Skinned multi-person linear model
Black, M.J., Loper, M., Mahmood, N., Pons-Moll, G., Romero, J.
December 2016, Application PCT/EP2016/064610 (patent)
Non-parametric Models for Structured Data and Applications to Human Bodies and Natural Scenes
2015
Shape Models of the Human Body for Distributed Inference
From Scans to Models: Registration of 3D Human Shapes Exploiting Texture Information

Long Range Motion Estimation and Applications
2014

Advanced Structured Prediction
Nowozin, S., Gehler, P. V., Jancsary, J., Lampert, C. H.
Advanced Structured Prediction, pages: 432, Neural Information Processing Series, MIT Press, November 2014 (book)
Modeling the Human Body in 3D: Data Registration and Human Shape Representation
Model transport: towards scalable transfer learning on manifolds - supplemental material
Freifeld, O., Hauberg, S., Black, M. J.
(9), April 2014 (techreport)
2013

Puppet Flow

Human Pose Calculation from Optical Flow Data

Statistics on Manifolds with Applications to Modeling Shape Deformations

A Quantitative Analysis of Current Practices in Optical Flow Estimation and the Principles Behind Them
Sun, D., Roth, S., Black, M. J.
(CS-10-03), Brown University, Department of Computer Science, January 2013 (techreport)
2012

Virtual Human Bodies with Clothing and Hair: From Images to Animation
Coregistration: Supplemental Material

Lie Bodies: A Manifold Representation of 3D Human Shape. Supplemental Material

MPI-Sintel Optical Flow Benchmark: Supplemental Material

From Pixels to Layers: Joint Motion Estimation and Segmentation

Consumer Depth Cameras for Computer Vision - Research Topics and Applications
Fossati, A., Gall, J., Grabner, H., Ren, X., Konolige, K.
Advances in Computer Vision and Pattern Recognition, Springer, 2012 (book)