A simple yet effective baseline for 3d human pose estimation
2017
Conference Paper
ps
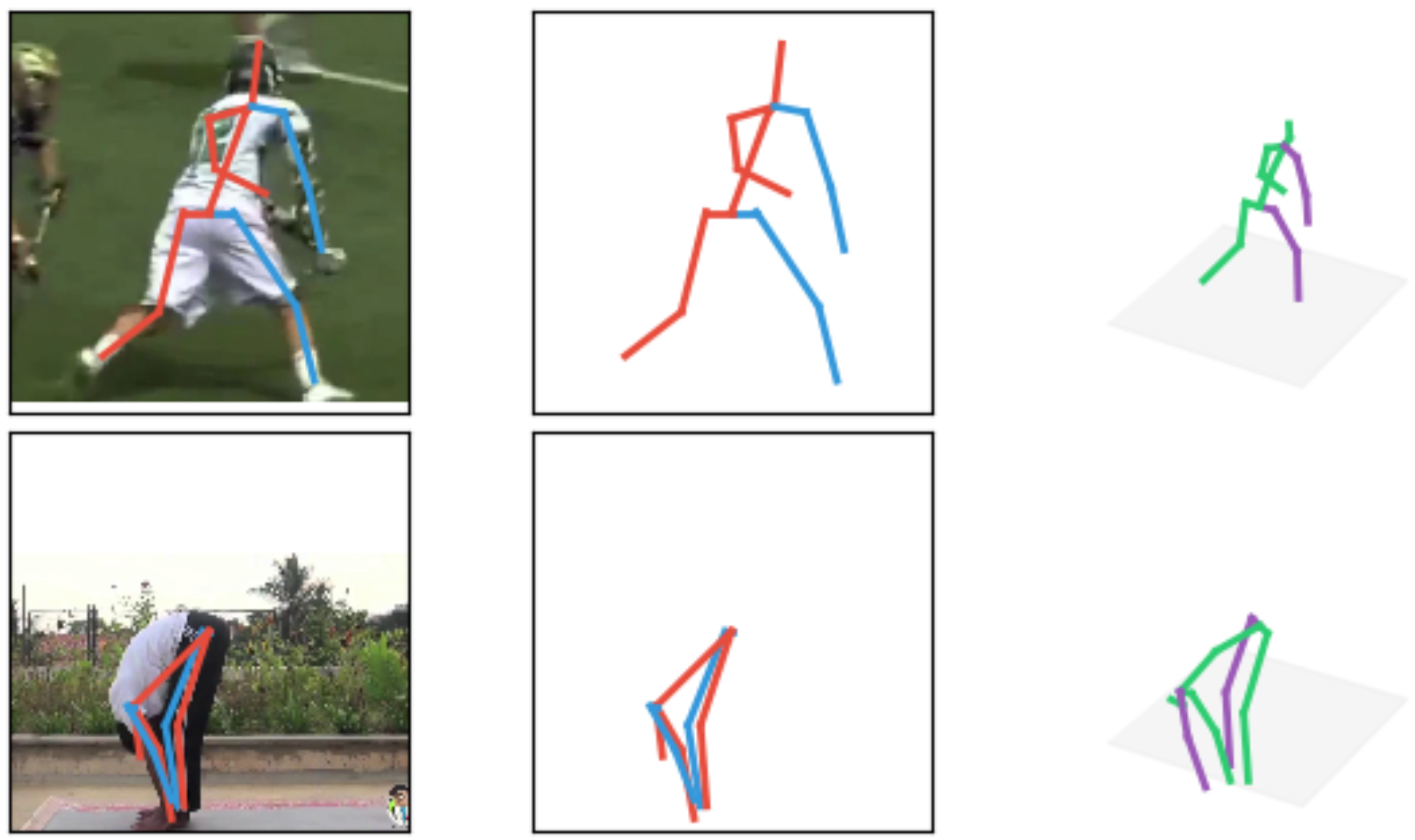
Following the success of deep convolutional networks, state-of-the-art methods for 3d human pose estimation have focused on deep end-to-end systems that predict 3d joint locations given raw image pixels. Despite their excellent performance, it is often not easy to understand whether their remaining error stems from a limited 2d pose (visual) understanding, or from a failure to map 2d poses into 3-dimensional positions. With the goal of understanding these sources of error, we set out to build a system that given 2d joint locations predicts 3d positions. Much to our surprise, we have found that, with current technology, "lifting" ground truth 2d joint locations to 3d space is a task that can be solved with a remarkably low error rate: a relatively simple deep feed-forward network outperforms the best reported result by about 30\% on Human3.6M, the largest publicly available 3d pose estimation benchmark. Furthermore, training our system on the output of an off-the-shelf state-of-the-art 2d detector (\ie, using images as input) yields state of the art results -- this includes an array of systems that have been trained end-to-end specifically for this task. Our results indicate that a large portion of the error of modern deep 3d pose estimation systems stems from their visual analysis, and suggests directions to further advance the state of the art in 3d human pose estimation.
| Author(s): | Julieta Martinez and Rayat Hossain and Javier Romero and James J. Little |
| Book Title: | Proceedings IEEE International Conference on Computer Vision (ICCV) |
| Year: | 2017 |
| Month: | October |
| Day: | 22-29 |
| Publisher: | IEEE |
| Department(s): | Perceiving Systems |
| Research Project(s): |
Modeling Human Movement
|
| Bibtex Type: | Conference Paper (inproceedings) |
| Paper Type: | Conference |
| Event Name: | IEEE International Conference on Computer Vision (ICCV) |
| Event Place: | Venice, Italy |
| Address: | Piscataway, NJ, USA |
| ISBN: | 978-1-5386-1032-9 |
| ISSN: | 2380-7504 |
| Links: |
video
code arxiv |
| Video: | |
| Attachments: |
pdf preprint
|
|
BibTex @inproceedings{JMartinez:ICCV:2017,
title = {A simple yet effective baseline for 3d human pose estimation},
author = {Martinez, Julieta and Hossain, Rayat and Romero, Javier and Little, James J.},
booktitle = {Proceedings IEEE International Conference on Computer Vision (ICCV)},
publisher = {IEEE},
address = {Piscataway, NJ, USA},
month = oct,
year = {2017},
doi = {},
month_numeric = {10}
}
|
|