Code and Data

BEDLAM: A Synthetic Dataset of Bodies Exhibiting Detailed Lifelike Animated Motion
2023-06-14
Synthetic image dataset (1.6 million images) with bodies in motion in realistic environments and trained HPS regressors using only this data. BEDLAM dataset contains monocular RGB videos with ground-truth 3D bodies in SMPL-X format. It includes a diversity of body shapes, motions, skin tones, hair, and clothing. The clothing is realistically simulated on the moving bodies using commercial clothing physics simulation. We render varying numbers of people in realistic scenes with varied lighting and camera motions. We then train various HPS regressors using BEDLAM and achieve state-of-the-art accuracy on real-image benchmarks despite training with synthetic data.
https://bedlam.is.tuebingen.mpg.de/
https://github.com/pixelite1201/BEDLAM
dataset images synthetic animation clothing hps SMPL-X

SUPR Convertor
2023-03-15
A utility tool to convert SMPL-X model parameters to SUPR model parameters.
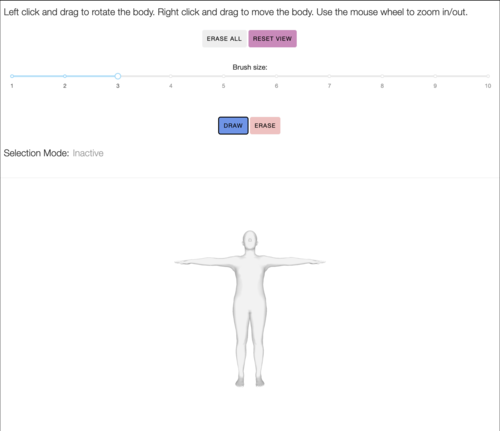
Mesh Annotator
2023-02-21
Contact labeling application for selecting body regions / mesh vertices on the Mechanical Turk.
python dash javascript docker ansible
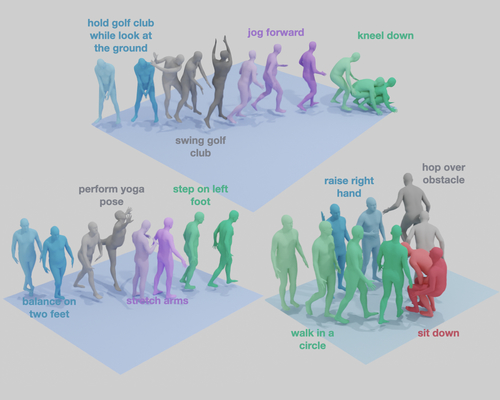
TEACH: Temporal Action Compositions for 3D Humans
2023-01-23
Official PyTorch implementation of the paper "TEACH: Temporal Action Compositions for 3D Humans".

EMOCA: Emotion Driven Monocular Face Capture and Animation
2022-04-07
EMOCA takes a single in-the-wild image as input and reconstructs a 3D face with sufficient facial expression detail to convey the emotional state of the input image. EMOCA advances the state-of-the-art monocular face reconstruction in-the-wild, putting emphasis on accurate capture of emotional content.
The repository provides:
- An approach to reconstruct animatable 3D faces from an in-the-wild images, that is capable of recovering facial expressions that convey the correct emotional state.
- A novel perceptual emotion-consistency loss that rewards the accuracy of the reconstructed emotion.
- A 3D geometry-based framework for in-the-wild emotion recognition, with comparable performance to current state-of-the-art image-based methods.
- Different pre-trained image-based emotion recognition networks.
https://github.com/radekd91/emoca
expression emotion FLAME face 3D head animation wrinkles shape mesh regression deep learning
Mechanical Turk Manager
2022-04-01
Web application for interfacing with the Amazon Mechanical Turk.
python django ansible mechanical turk

DIGIT
2021-11-26
DIGIT estimates the 3D poses of two interacting hands from a single RGB image. This repo provides the training, evaluation, and demo code for the project in PyTorch Lightning.

SAMP: Stochastic Scene-Aware Motion Prediction
2021-11-05
SAMP generates a 3D human avatar that navigates a novel scene to achieve goals. The software includes runtime Unity code and training code as well as training data.
https://github.com/mohamedhassanmus/SAMP
avatar digital human motion synthesis human movement affordance neural network contact mocap

ROMP: Monocular, One-Stage, Regression of Multiple 3D People
2021-10-13
ROMP estimates multiple 3D people in an image in real time. Unlike prior methods, it does not first detect the people and then estimate their pose. Instead, ROMP estimates the a heatmap corresponding to the centers of people together with the parameters of the SMPL model at these centers. The code includes realtime demos.
https://github.com/Arthur151/ROMP
human pose 3D body body shape SMPL deep learning realtime learning mesh computer vision
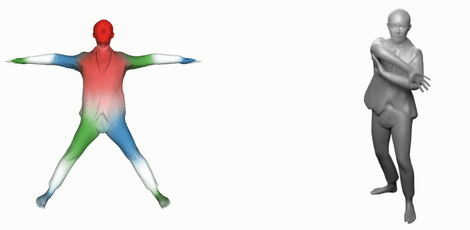
SNARF: Differentiable Forward Skinning for Animating Non-rigid Neural Implicit Shapes
2021-10-13
Official code release for ICCV 2021 paper SNARF: Differentiable Forward Skinning for Animating Non-rigid Neural Implicit Shapes. We propose a novel forward skinning module to animate neural implicit shapes with good generalization to unseen poses. Given scans of a person, SNARF creates an animatable implicit avatar. Training and animation code is included.
https://github.com/xuchen-ethz/snarf
implicit shape clothing human pose 3D shape animation learning deep learning avatar digital human skinning
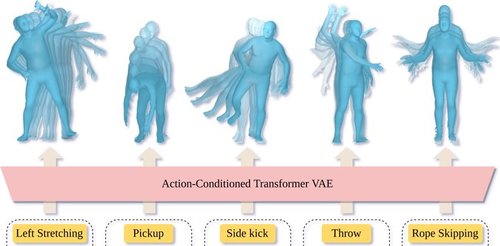
ACTOR: Action-Conditioned 3D Human Motion Synthesis with Transformer VAE
2021-10-13
ACTOR learns an action-aware latent representation for human motions by training a generative variational autoencoder (VAE). By sampling from this latent space and querying a certain duration through a series of positional encodings, we synthesize variable-length motion sequences conditioned on a categorical action. ACTOR uses a transformer-based architecture to encode and decode a sequence of parametric SMPL human body models estimated from action recognition datasets.
https://github.com/Mathux/ACTOR
SMPL VAE transformer motion synthesis action

The Power of Points for Modeling Humans in Clothing
2021-10-12
PoP (Power of Points) is a point-based model for generating high-fidelity dense point clouds of humans in clothing with pose-dependent geometry. It supports modeling multiple subjects of varied body shapes and different outfit types with a single model. At test-time, given a single, static scan, the model can animate it with plausible pose-dependent deformations.
https://qianlim.github.io/POP
https://github.com/qianlim/POP
Clothing garment geometry shape analysis 3D pose scan animation
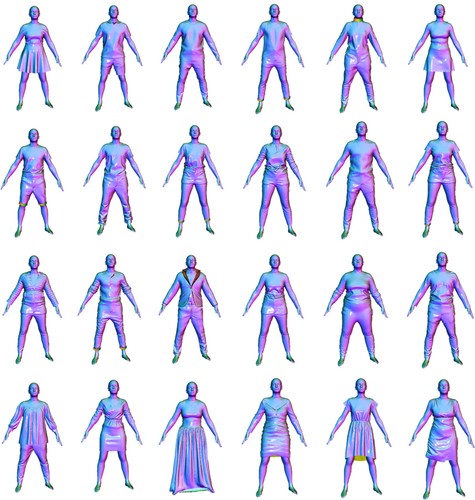
ReSynth Dataset
2021-10-12
The ReSynth Dataset is a synthetic dataset of 3D clothed humans in motion, created using physics based simulation. The dataset contains 24 outfits of diverse garment types, dressed on varied body shapes across both genders. All outfits are simulated using a consistent set of 20 motion sequences captured in the CAPE dataset. We provide both the simulated high-res point clouds as well as the packed data that's ready to run with the model introduced in the ICCV 2021 paper "The Power of Points for Modeling Humans in Clothing". Checkout out the dataset website for more information.
simulation synthetic data clothing garment geometry shape analysis 3D pose animation

PARE: Part Attention Regressor for 3D Human Body Estimation
2021-10-12
PARE regresses 3D human pose and shape using part-guided attention. It learns to be robust to occlusion, making it much more practical than recent methods when applied to real images.
https://pare.is.tue.mpg.de/
https://github.com/mkocabas/PARE

SPEC: Seeing People in the Wild with an Estimated Camera
2021-10-12
SPEC is the first in-the-wild 3D HPS method that estimates the perspective camera from a single image and employs this to reconstruct 3D human bodies more accurately.
https://spec.is.tue.mpg.de/
https://github.com/mkocabas/SPEC

SPEC dataset: Pano360, SPEC-SYN, SPEC-MTP
2021-10-12
Pano360 dataset consists of 35K panoramic images of which 34K are from Flickr and 1K rendered from photorealistic 3D scenes. We use it to train CamCalib. SPEC-SYN is a photorealistic synthetic dataset which has accurate ground-truth SMPL and camera annotations. We use it for both training and evaluating SPEC. SPEC-MTP is a crowdsourced dataset consisting of real images, camera calibration and SMPL-X fits. We use it only for evaluation purposes in the experiment.
https://spec.is.tue.mpg.de/
https://github.com/mkocabas/SPEC#datasets
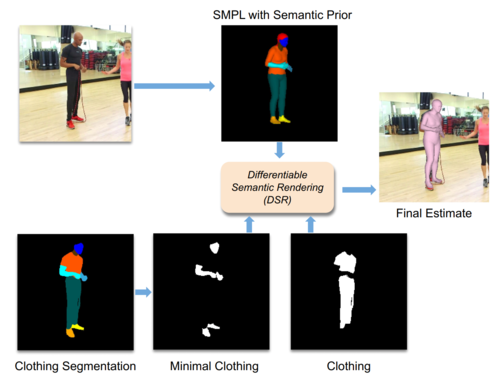
Learning to Regress Bodies from Images using Differentiable Semantic Rendering
2021-10-12
DSR uses semantic information in the form of clothing segmentation when learning to regress 3D human pose and shape from an image. The SMPL body should fit inside the clothing and match unclothed regions.
Active Domain Adaptation via Clustering Uncertainty-weighted Embeddings
2021-10-10
Generalizing deep neural networks to new target domains is critical to their real-world utility. While labeling data from the target domain, it is desirable to select a subset that is maximally-informative to be cost-effective (called Active Learning). The ADA-CLUE algorithm addresses the problem of Active Learning under a domain shift. The GitHub repo consists of code to train models with the ADA-CLUE algorithm for multiple source and target domain shifts. Pre-trained models are also available.
https://github.com/virajprabhu/CLUE
active learning domain adaptation image classification

SOMA: Solving Optical Marker-Based MoCap Automatically
2021-10-09
Marker-based optical motion capture systems, in short mocap, are an ultimate precision tool to capture motion of objects and bodies. However, the raw output of these systems are unordered sparse point clouds that have to be brought into correspondence with physical markers on the surface. SOMA is a machine learning-based tool that automates this process, replacing the human expert in the loop, thus enabling rapid production of high quality data with applications in computer graphics and computer vision.
https://soma.is.tue.mpg.de/
https://github.com/nghorbani/soma
mocap marker-based mocap point cloud smpl smplx
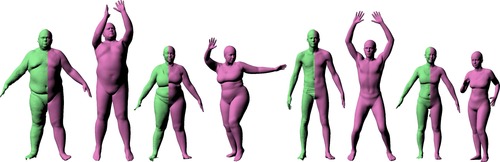
MoSh: Motion and Shape Capture from Sparse Markers
2021-10-09
MoSh can fit surface models of human, animal, and objects to marker-based motion capture, in short mocap, data with high accuracy second only to that of 4D scan data. Fitting is completely automatic, given labeled, and clean mocap marker data. The labeling can also be made automatic using SOMA, whose code is also released here.

3DCP: 3D Contact Poses
2021-10-06
The 3D Contact Poses dataset contains SMPL-X bodies fit to 3D scans of five subjects in various self-contact poses, as well as self-contact optimised meshes from the AMASS motion capture dataset.
https://tuch.is.tue.mpg.de
https://github.com/muelea/selfcontact

SAMP Dataset
2021-08-17
SAMP dataset is high-quality MoCap data covering various sitting, lying down, walking, and running styles. We capture the motion of the body as well as the object.
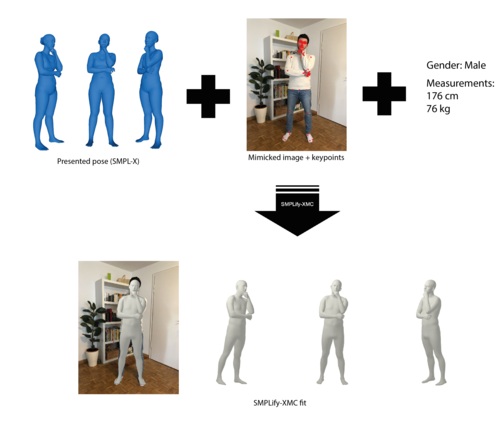
SMPLify-XMC: On Self-Contact and Human Pose
2021-06-22
SMPLify-XMC is a SMPLify-X optimization framework with Mimicked Contact. It fits a SMPL-X body to a image given (1) 2D keypoints, (2) a known 3D body pose and self-contact, (3) gender, height and weight as input. SMPLify-XMC is used in MTP (Mimic-The-Pose) data collection pipeline to create near ground-truth SMPL-X parameters and self-contact for each in-the-wild image.
https://tuch.is.tue.mpg.de/
https://github.com/muelea/smplify-xmc
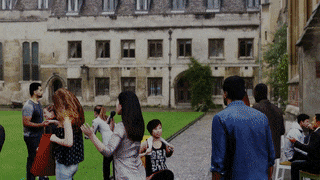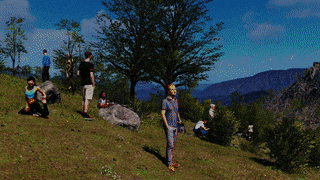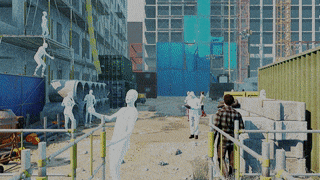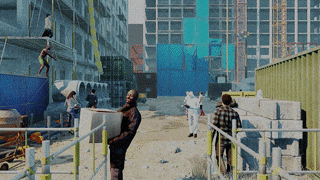
AGORA dataset
2021-06-22
While the accuracy of 3D human pose estimation from images has steadily improved on benchmark datasets, the best methods still fail in many real-world scenarios. This suggests that there is a domain gap between current datasets and common scenes containing people. To evaluate the current state-of-the-art methods on more challenging images, and to drive the field to address new problems, we introduce AGORA, a synthetic dataset with high realism and highly accurate ground truth. We create around 14K training and 3K test images by rendering between 5 and 15 people per image using either image-based lighting or rendered 3D environments, taking care to make the images physically plausible and photoreal. In total, AGORA consists of 173K individual person crops.
https://agora.is.tue.mpg.de/
https://github.com/pixelite1201/agora_evaluation

SCALE: Modeling Clothed Humans with a Surface Codec of Articulated Local Elements
2021-06-22
SCALE learns a representation of 3D humans in clothing that generalizes to new body poses. SCALE is a point-based representation based on a collection of local surface elements. The code enables people to train and animate SCALE models and includes examples from the CAPE dataset.
https://github.com/qianlim/SCALE
3D human digital human body shape human pose clothing point cloud deep learning shape model

SCANimate: Weakly Supervised Learning of Skinned Clothed Avatar Networks
2021-06-21
SCANimate is an end-to-end trainable framework that takes raw 3D scans of a clothed human and turns them into an animatable avatar. These avatars are driven by pose parameters and have realistic clothing that moves and deforms naturally. SCANimate uses an implicit shape representation and does not rely on a customized mesh template or surface mesh registration.
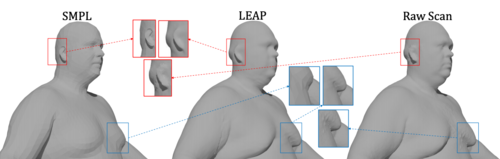
LEAP: Learning Articulated Occupancy of People
2021-06-18
LEAP (LEarning Articulated occupancy of People), a novel neural occupancy representation of the human body. It is effectively an implitic version of SMPL. Given a set of bone transformations (i.e. joint locations and rotations) and a query point in space, LEAP first maps the query point to a canonical space via learned linear blend skinning (LBS) functions and then efficiently queries the occupancy value via an occupancy network that models accurate identity- and pose- dependent deformations in the canonical space.
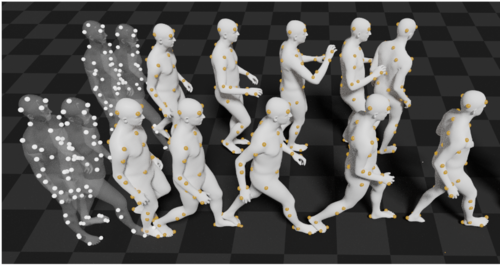
MOJO: We are More than Our Joints
2021-06-18
MOJO (More than Our JOints) is a novel variational autoencoder with a latent DCT space that generates 3D human motions from latent frequencies. MOJO preserves the full temporal resolution of the input motion, and sampling from the latent frequencies explicitly introduces high-frequency components into the generated motion. We note that motion prediction methods accumulate errors over time, resulting in joints or markers that diverge from true human bodies. To address this, we fit the SMPL-X body model to the predictions at each time step, projecting the solution back onto the space of valid bodies, before propagating the new markers in time. Quantitative and qualitative experiments show that our approach produces state-of-the-art results and realistic 3D body animations.
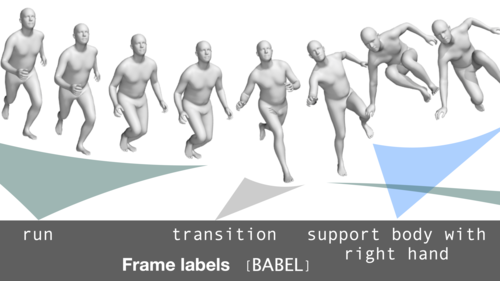
BABEL: Bodies, Action and Behavior with English Labels
2021-06-18
The BABEL dataset consists of labels that describe the action being performed in a mocap sequence. There are two types of labels — sequence labels that describe the actions being performed in the entire sequence, and fine-grained frame labels that describe the actions being performed in each frame. The mocap sequences in BABEL are derived from the AMASS dataset. The GitHub repo consists of helper code that loads and filters the data based on labels. It also consists of training code, features, and pre-trained models that perform the task of action recognition on the BABEL dataset.
https://babel.is.tue.mpg.de/
https://github.com/abhinanda-punnakkal/BABEL
actions language mocap action recognition

SMPL-X for Blender and Unity
2021-06-17
We facilitate the use of SMPL-X in popular third-party applications by providing dedicated add-ons for Blender and Unity. The SMPL-X 1.1 model can now be quickly added as a textured skeletal mesh with a shape specific rig, as well as shape keys (blend shapes) for shape, expression and pose correctives. We also provide functionality to recalculate joint locations on shape change and proper activation of pose correctives after pose changes.
smpl-x blender unity

SMPLpix: Neural Avatars from 3D Human Models
2021-05-03
SMPLpix is a neural rendering framework that combines deformable 3D models such as SMPL-X with the power of image-to-image translation frameworks (aka pix2pix models). Create a 3D avatar from an video and then render it in new poses.
https://github.com/sergeyprokudin/smplpix
human pose 3D body SMPL deep learning clothing learning mesh rendering neural computer vision AI

DECA: Learning an Animatable Detailed 3D Face Model from In-the-Wild Images
2021-05-03
DECA reconstructs a 3D head model with detailed facial geometry from a single input image. The resulting 3D head model can be easily animated. The main features: * Reconstruction: produces head pose, shape, detailed face geometry, and lighting information from a single image. * Animation: animate the face with realistic wrinkle deformations. * Robustness: tested on facial images in unconstrained conditions. Our method is robust to various poses, illuminations and occlusions. * Accurate: state-of-the-art 3D face shape reconstruction on the NoW Challenge benchmark dataset.
https://github.com/YadiraF/DECA
face FLAME expression 3D head animation wrinkles shape mesh regression deep learning disentanglement

POSA: Populating 3D Scenes by Learning Human-Scene Interaction
2021-04-28
POSA takes a 3D body and automatically places it in a 3D scene in a semantically meaningful way. This repository contains the training, random sampling, and scene population code used for the experiments in POSA. The code defines a novel representation of human-scene-interaction that is body centric. This can be exploited for 3D human tracking from video to model likely interactions between a body and the scene.
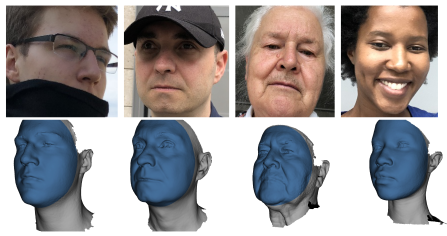
NoW Evaluation: Learning to Regress 3D Face Shape and Expression from an Image without 3D Supervision
2021-02-12
Code: We provide the evaluation code for NoW challenge proposed in the RingNet paper. Please check the repository which is self-explanatory. NoW Benchmark Dataset and Challenge: Please check the external link to download the data and participate in the challenge.
https://ringnet.is.tue.mpg.de
https://github.com/soubhiksanyal/now_evaluation

GIF: Generative Interpretable Faces
2020-12-16
GIF is a photorealistic generative face model with explicit control over 3D geometry (parametrized like FLAME), appearance, and lighting. Training and animation code is provided.
https://github.com/ParthaEth/GIF
Generative Interpretable Faces conditional generative models 3D conditioning of GANs explicit 3D control of photorealistic faces Photorealistic faces.
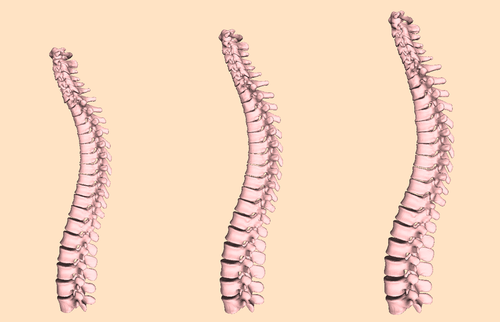
Learning a statistical full spine model from partial observations
2020-11-11
The study of the morphology of the human spine has attracted research attention for its many potential applications, such as image segmentation, bio-mechanics or pathology detection. However, as of today there is no publicly available statistical model of the 3D surface of the full spine. This is mainly due to the lack of openly available 3D data where the full spine is imaged and segmented. In this paper we propose to learn a statistical surface model of the full-spine (7 cervical, 12 thoracic and 5 lumbar vertebrae) from partial and incomplete views of the spine. In order to deal with the partial observations we use probabilistic principal component analysis (PPCA) to learn a surface shape model of the full spine. Quantitative evaluation demonstrates that the obtained model faithfully captures the shape of the population in a low dimensional space and generalizes to left out data. Furthermore, we show that the model faithfully captures the global correlations among the vertebrae shape. Given a partial observation of the spine, i.e. a few vertebrae, the model can predict the shape of unseen vertebrae with a mean error under 3 mm. The full-spine statistical model is trained on the VerSe 2019 public dataset and is publicly made available to the community for non-commercial purposes. (https://gitlab.inria.fr/spine/spine_model)
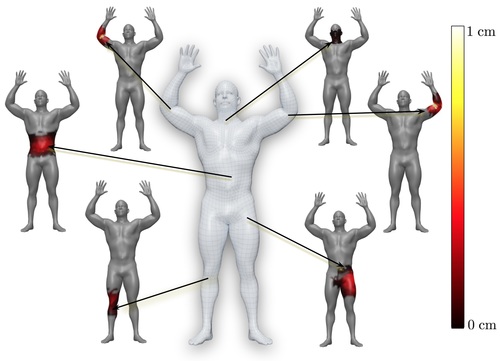
STAR: A Sparse Trained Articulated Human Body Regressor
2020-08-26
We propose STAR, a realistic human body with a learned set of sparse and spatially local pose corrective blend shapes. STAR addresses many of the drawbacks of the widely used SMPL model despite having an order of magnitude fewer parameters. The code released includes the model implementation in Tensorflow, PyTorch, and Chumpy.
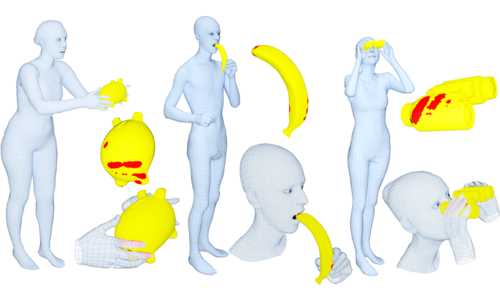
GRAB: A Dataset of Whole-Body Human Grasping of Objects
2020-08-25
Training computers to understand, model, and synthesize human grasping requires a rich dataset containing complex 3D object shapes, detailed contact information, hand pose and shape, and the 3D body motion over time. While "grasping" is commonly thought of as a single hand stably lifting an object, we capture the motion of the entire body and adopt the generalized notion of "whole-body grasps". Thus, we collect a new dataset, called GRAB (GRasping Actions with Bodies), of whole-body grasps, containing full 3D shape and pose sequences of 10 subjects interacting with 51 everyday objects of varying shape and size. The dataset contains 1.622.459 frames in total. Each one has (1) an expressive 3D SMPL-X human mesh (shaped and posed), (2) a 3D rigid object mesh (posed), and (3) contact annotations (wherever applicable).
https://grab.is.tue.mpg.de
https://github.com/otaheri/GRAB
SMPL-X grasp whole-body human-object interaction hand-object interaction whole-body interaction
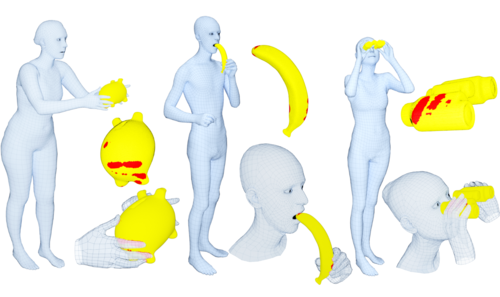
GrabNet: Generating 3D hand grasps for unseen 3D objects
2020-08-24
There is a significant interest in the community in training models to grasp 3D objects. This is important for example for interacting human avatars, as well as for robotic grasping by imitating human grasping. We use our GRAB dataset (see entry above) of whole-body grasps, and extract hand-only information. We then train on this our deep-net model GrabNet to generate 3D hand grasps, using our hand model MANO, for unseen 3D objects. We provide both the GrabNet model and its training dataset for research purposes.
https://grab.is.tue.mpg.de
https://github.com/otaheri/GrabNet
grasp grasp generation hand-object interaction

ExPose: EXpressive POse and Shape rEgression
2020-08-23
Training models to quickly and accurately estimate expressive humans (SMPL-X) from an RGB image, including the main body, face and hands, is challenging for a number of reasons. First, there exists no dataset with paired images and ground truth SMPL-X annotations. Secondly, the face and hands take up much fewer pixels than the main body, making inference harder. Third, full body images are further downsampled to use with contemporary methods. Here we provide the first dataset of 32.617 pairs of: (1) an in-the-wild RGB image, and (2) an expressive whole-body 3D human reconstruction (SMPL-X), created by carefully curating the results of our earlier SMPLify-X method on a big number of datasets. We also provide ExPose, the first deep-net model that quickly predicts expressive 3D human bodies from a single RGB image, trained on this dataset. ExPose is 200x faster than SMPLify-X, while being on par in overall accuracy. The dataset can be used to train other similar models.
http://expose.is.tue.mpg.de
https://github.com/vchoutas/expose
expressive humans humans from images SMPL-X regression

Generating 3D People in Scenes without People
2020-06-18
Our PSI system aims to generate 3D people in a 3D scene from the view of an agent. The system takes as input the depth and the semantic segmentation from a camera view, and generates plausible SMPL-X body meshes, which are naturally posed in the 3D scene. Scripts of data pre-processing, training, fitting, evaluation and visualization, as well as the data, are incorporated.

CAPE: Dressing SMPL
2020-06-17
CAPE provides a "dressed SMPL" body model. We train CAPE as a conditional Mesh-VAE-GAN to learn the clothing deformation from the SMPL body model, making clothing an additional term on SMPL. CAPE is conditioned on both pose and clothing type, giving the ability to draw samples of clothing to dress different body shapes in a variety of styles and poses.
https://cape.is.tue.mpg.de/
https://github.com/QianliM/CAPE
human pose 3D body SMPL deep learning clothing learning mesh autoencoder GAN VAE wrinkles computer vision AI

VIBE: Video Inference for Human Body Pose and Shape Estimation
2020-02-27
VIBE is a neural network method that takes video of a human in motion as input and outputs the 3D pose and shape of the body in every frame. The output is in SMPL body format and represents the state of the art at time of release. The method runs quickly and can process arbitrary sequence lengths. The trained model is available now and training code will be provided later.
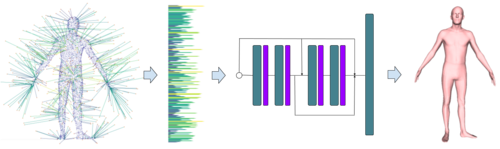
Efficient Learning on Point Clouds with Basis Point Sets
2019-12-23
Basis Point Set (BPS) is a simple and efficient method for encoding 3D point clouds into fixed-length representations. It is based on a simple idea: select k fixed points in space and compute vectors from these basis points to the nearest points in a point cloud; use these vectors (or simply their norms) as features. The basis points are kept fixed for all the point clouds in the dataset, providing a fixed representation of every point cloud as a vector. This representation can then be used as input to arbitrary machine learning methods, in particular it can be used as input to off-the-shelf neural networks.
https://github.com/sergeyprokudin/bps
point clouds 3D data analysis basis point sets

Markerless Outdoor Human Motion Capture Using Multiple Autonomous Micro Aerial Vehicles
2019-10-19
Capturing human motion in natural scenarios means moving motion capture out of the lab and into the wild. Typical approaches rely on fixed, calibrated, cameras and reflective markers on the body, significantly limiting the motions that can be captured. To make motion capture truly unconstrained, we describe the first fully autonomous outdoor capture system based on flying vehicles. We use multiple micro-aerial-vehicles(MAVs), each equipped with a monocular RGB camera, an IMU, and a GPS receiver module. These detect the person, optimize their position, and localize themselves approximately. We then develop a markerless motion capture method that is suitable for this challenging scenario with a distant subject, viewed from above, with approximately calibrated and moving cameras. We combine multiple state-of-the-art 2D joint detectors with a 3D human body model and a powerful prior on human pose. We jointly optimize for 3D body pose and camera pose to robustly fit the 2D measurements. To our knowledge, this is the first successful demonstration of outdoor, full-body, markerless motion capture from autonomous flying vehicles.
https://aircapdata.is.tue.mpg.de/aircapposeestimator.html
https://github.com/robot-perception-group/Aircap_Pose_Estimator

SPIN: Human pose and shape from an image
2019-10-01
SPIN is a state-of-the-art deep network for regressing SMPL body shape and pose parameters directly from an image. SPIN uses a novel training method that combines a bottom-up deep network with a top-down, model-based, fitting method. SMPLify model fitting is used in the loop with the DNN training to provide SMPL parameters used in the training loss. Code is available.
https://www.seas.upenn.edu/~nkolot/projects/spin/
https://github.com/nkolot/SPIN
human pose 3D body SMPL deep learning SMPLify

AMASS Dataset
2019-09-13
AMASS is a large dataset of human motions - 45 hours and growing. AMASS enables the training of deep neural networks to model human motion. AMASS unifies multiple datasets by fitting the SMPL body model to mocap markers. The dataset includes SMPL-H body shapes and poses as well as DMPL soft tissue motions. If you want to include your own mocap sequences in the dataset, please contact us. The release includes tutorial code for training DNNs with AMASS. Also the MoSh++ code is now available. We also release SOMA, our complementary tool for automatic mocap labeling.
https://amass.is.tue.mpg.de/
https://github.com/nghorbani/amass
mocap motion capture 3D body SMPL MoSh deep learning

Three-D Safari: Learning to Estimate Zebra Pose, Shape, and Texture from Images "In the Wild"
2019-09-11
We present the first method to perform automatic 3D pose, shape and texture capture of animals from images acquired in-the-wild. In particular, we focus on the problem of capturing 3D information about Grevy's zebras from a collection of images. We integrate the recent SMAL animal model into a network-based regression pipeline, which we train end-to-end on synthetically generated images with pose, shape, and background variation. We couple 3D pose and shape prediction with the task of texture synthesis, obtaining a full texture map of the animal from a single image. The predicted texture map allows a novel per-instance unsupervised optimization over the network features. We called the method SMALST (SMAL with learned Shape and Texture).
https://github.com/silviazuffi/smalst
3D animal pose estimation; animal shape
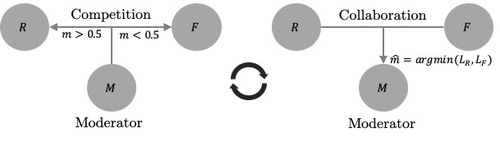
Competitive Collaboration
2019-07-18
Competitive Collaboration is a generic framework in which networks learn to collaborate and compete, thereby achieving specific goals. Competitive Collaboration is a three player game consisting of two players competing for a resource that is regulated by a third player, moderator. This framework is similar in spirit to expectation-maximization (EM) but is formulated for neural network training.
https://github.com/anuragranj/cc
unsupervised-learning; depth; optical-flow; odometry; camera-motion; segmentation; competitive; collaboration

Learning joint reconstruction of hands and manipulated objects
2019-06-14
Estimating hand-object manipulation is essential for interpreting and imitating human actions. Previous work has made significant progress towards reconstruction of hand poses and object shapes in isolation. Yet, reconstructing hands and objects during manipulation is a more challenging task due to significant occlusions of both the hand and object. While presenting challenges, manipulations may also simplify the problem since the physics of contact restricts the space of valid hand-object configurations. For example, during manipulation, the hand and object should be in contact but not interpenetrate. In this work we regularize the joint reconstruction of hands and objects with manipulation constraints. We provide an end-to-end learnable model that exploits a novel contact loss that favors physically plausible hand-object constellations. To train and evaluate the model, we also provide a new large-scale synthetic dataset, ObMan, with hand-object manipulations. Our approach significantly improves grasp quality metrics over baselines on synthetic and real datasets, using RGB images as input.
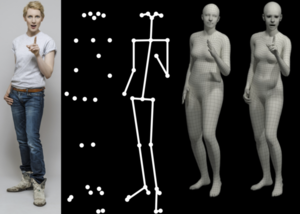
Expressive Body Capture: 3D Hands, Face, and Body from a Single Image
2019-06-14
SMPL-X is a major update to the SMPL body model that adds an expressive face and fully articulated hands. If you use SMPL, this is a straightforward upgrade that improves realism and allows you to capture facial expressions and gestures. We also provide SMPLify-X to estimate SMPL-X from a single image. This is a major update to SMPlify in several senses: (1) we detect 2D features corresponding to the face, hands, and feet and fit the full SMPL-X model to these; (2) we train a new neural network pose prior using a large MoCap dataset; (3) we define a new interpenetration penalty that is both fast and accurate; (4) we automatically detect gender and the appropriate body models (male, female, or neutral); (5) our PyTorch implementation achieves a speedup of more than 8x over Chumpy.
https://smpl-x.is.tue.mpg.de
https://github.com/vchoutas/smplify-x

RingNet: Learning to Regress 3D Face Shape and Expression from an Image without 3D Supervision
2019-05-10
Code: We provide the inference code of RingNet. Please check the repository which is self explanatory. NoW Benchmark Dataset and Challenge: Please check the external link to download the data and participate in the challenge.
https://ringnet.is.tue.mpg.de
https://github.com/soubhiksanyal/RingNet

VOCA: Capture, Learning, and Synthesis of 3D Speaking Styles
2019-05-01
VOCA (Voice Operated Character Animation) is a framework that takes a speech signal as input and realistically animates a wide range of adult faces.
Code: We provide Python demo code that outputs a 3D head animation given a speech signal and a static 3D head mesh. The codebase further provides animation control to alter the speaking style, identity-dependent facial shape, and head pose (i.e. head rotation around the neck) during animation. The code further demonstrates how to sample 3D head meshes from the publicly available FLAME model, that can then be animated with the provided code.
Dataset: We capture a unique 4D face dataset (VOCASET) with about 29 minutes of 3D scans captured at 60 fps and synchronized audio from 12 speakers. We provide the raw 3D scans, registrations in FLAME topology, and unposed registrations (i.e. registrations in "zero pose").
https://voca.is.tue.mpg.de
https://github.com/TimoBolkart/voca

The Virtual Caliper: Rapid Creation of Metrically Accurate Avatars from 3D Measurements
2019-03-26
The Virtual Caliper project provides you with software tools to rapidly generate metrically accurate avatars based on measurements. These avatars can be generated offline in FBX format for later import into game engines or alternatively within the game engine itself. Avatars are based on the SMPL body model and support skeletal mesh animation. Released software includes Unity project files and standalone binaries for Windows/Linux/macOS and Blender Python code for FBX generation.

Monocle
2019-02-24
Application used for capturing from the Kinect 2.0 device.
https://github.com/MPI-IS/monocle
c# kinect sdk makefile

Deep Inertial Poser: Learning to Reconstruct Human Pose from Sparse Inertial Measurements in Real Time
2018-10-16
This is the code for our SIGGRAPH Asia 2018 project
http://dip.is.tuebingen.mpg.de/
https://github.com/eth-ait/dip18
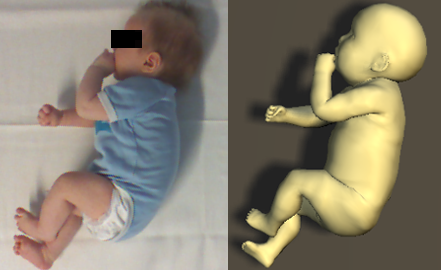
Skinned Multi-Infant Linear Model (SMIL)
2018-09-16
SMIL is a learned 3D model of infant body shape and pose that can be animated and fit to data. It is based on SMPL but the shape space is adapted to capture the body shape of babies.
infant body model pose shape baby RGB-D movement mocap

3D Poses in the Wild Dataset
2018-09-12
The "3D Poses in the Wild dataset" is the first dataset with monocular hand-held video together with accurate 3D human poses for evaluation. Our method combines video and IMU to recover accurate 3D human body models and their projection into the video sequences. The dataset includes: 60 video sequences; 2D pose annotations; 3D poses obtained with our method; Camera poses for every frame in the sequences; 3D body scans; and 18 3D human models with different clothing variations.
http://virtualhumans.mpi-inf.mpg.de/3DPW/
IMU pose 3D ground truth

Convolutional Mesh Autoencoders
2018-09-08
The code allows to build convolutional networks on mesh structures analogous to CNNs on images. The code includes mesh convolutions, and introduces downsampling and upsampling operators that can be directly applied to the mesh structure. The code implements a Convolution Mesh Autoencoder using the above mesh processing operators and achieves state of the art results on generating 3D facial meshes.
http://coma.is.tue.mpg.de/
https://github.com/anuragranj/coma
face mesh convolutions autoencoder

Mesh Library
2018-08-17
When working in 3D graphics, one needs to load raw data, conduct various processing on it, visualize the results to help understanding, then save the output in different kinds of formats. Here we release the Mesh Library to facilitate all these aforementioned operations. This library is built on top of OpenGL and CGAL, with an easy-to-use Python interface. Other than the basic usages like data IO and interactive visualization, it also supports other more complex functionalities like texture rendering, visibility computation, and geometry arithmetic. We hope the release of this tool makes the entry to 3D world smoother for interested people.
https://github.com/MPI-IS/mesh
mesh library 3d graphics

Learning Human Optical Flow
2018-07-12
The optical flow of humans is well known to be useful for the analysis of human action. Given this, we devise an optical flow algorithm specifically for human motion and show that it is superior to generic flow methods. Designing a method by hand is impractical, so we develop a new training database of image sequences with ground truth optical flow. For this we use a 3D model of the human body and motion capture data to synthesize realistic flow fields. We then train a convolutional neural network to estimate human flow fields from pairs of images. Since many applications in human motion analysis depend on speed, and we anticipate mobile applications, we base our method on SpyNet with several modifications. We demonstrate that our trained network is more accurate than a wide range of top methods on held-out test data and that it generalizes well to real image sequences. When combined with a person detector/tracker, the approach provides a full solution to the problem of 2D human flow estimation. Both the code and the dataset are available for research.

SMALR: Capturing Animal Shape and Texture from Images
2018-06-20
The SMALR release includes an updated SMAL model of animals and 3D animal models recovered from images. SMALR is the Skinned Multi-Animal Linear Model with Refinement. All the 3D shapes from the CVPR paper are available for download as 3D meshes, which can be posed and animated. As we create new meshes, they will be added here.
Accelerated K-means
2018-06-15
An efficient and generic implementation of the k-means clustering algoriothm.
c++ boost cmake cython python matlab

HMR: End-to-end Recovery of Human Shape and Pose
2018-03-30
Trained model to estimate 3D human shape and pose directly from an image. The input is pixels, and the output is a 3D body in SMPL format (shape parameters and pose parameters). Also provided is the code and data needed to train the model.
https://akanazawa.github.io/hmr/
https://github.com/akanazawa/hmr
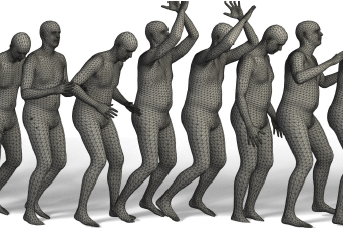
Towards Accurate Marker-less Human Shape and Pose Estimation over Time
2017-12-01
Model-based reconstruction of 3D SMPL body shape and pose from multi-view images. 2D joints and silhouettes from multi-view are used in the process. And DCT-based temporal prior is utilized to regularize the recovered 3D joint trajectory.

MANO: 3D hand model
2017-11-27
Data, code and model. This includes over 1000 3D hand scans and aligned meshes, the learned 3D hand shape model, the full articulated hand model with pose-dependent blend shapes. Also included is the SMPL body model with the hands attached to it, providing a realistic hand and body model.

FLAME: 3D model of facial shape and expression
2017-11-27
FLAME is a lightweight and expressive generic head model learned from over 33,000 of accurately aligned 3D scans. We provide the trained 3D face models, registrations for the dynamic D3DFACS dataset, and demo code in Chumpy and Tensorflow to load and sample the model, and to fit the model to 3D landmarks.
http://flame.is.tue.mpg.de/
https://github.com/TimoBolkart/TF_FLAME
head model face model morphable-model

SURREAL: Synthetic human dataset and trained networks
2017-07-21
First large-scale person dataset to generate depth, body parts, optical flow, 2D/3D pose, surface normals ground truth for RGB video input. The dataset contains 6M frames of synthetic humans. The images are photo-realistic renderings of people under large variations in shape, texture, view-point and pose. To ensure realism, the synthetic bodies are created using the SMPL body model, whose parameters are fit by the MoSh method given raw 3D MoCap marker data. Trained CNNs are also provided.
http://www.di.ens.fr/willow/research/surreal/
https://github.com/gulvarol/surreal

BUFF: Bodies under Flowing Fashion, 4D dataset
2017-07-21
High quality 4D dataset of people in clothing with ground truth 3D shape. The BUFF dataset consists of 5 subjects, 3 male and 2 female wearing 2 clothing styles: a) t-shirt and long pants and b) a soccer outfit. They perform 3 different motions i) hips ii) tilt_twist_left iii) shoulders_mill.

Dynamic FAUST
2017-07-21
This dataset is a unique resource containing over 40,000 4D scans of multiple people; 4D means 3D scans over time. Processing 4D data is challenging, so we provide aligned data in which we have registered a common template mesh to all scans. This alignment process takes into account geometry and surface texture to make it accurate. The dataset includes the raw scan data, registered template meshes, and masks that say where the template mesh is sufficiently accurate to be considered ground truth.

SMAL: 3D articulated model of animals shapes
2017-07-21
We provide the SMAL model of animal shapes and demo code. We also provide all the results from the CVPR paper of animal shapes estimated from images. We do not provide the 3D scans of the toy animals for copyright reasons but do provide a shopping list so that you can purchase the same toys that we used.

Unite the People – Closing the Loop Between 3D and 2D Human Representations
2017-07-21
The dataset includes annotations of common human pose datasets. These include 3D body pose, 91 surface and joint landmarks, foreground segmentation, and body part segments. Together with the images, these can be used to train neural networks for human pose estimation tasks, including 3D pose estimation. The 3D body is represented by SMPL. Training code is provided.
http://files.is.tuebingen.mpg.de/classner/up/
https://github.com/classner/up

MR-Flow: Optical flow in mostly-rigid scenes
2017-07-01
Code for the paper "Optical Flow in Mostly Rigid Scenes" by Jonas Wulff, Laura Sevilla-Lara, Michael Black, CVPR 2017. This is one of the best performing methods across different datasets. In rigid parts of the scene, a plane-plus-parallax model is used. The method segments out the non-rigid regions and uses a more generic flow method there.
https://ps.is.tuebingen.mpg.de/publications/wulff-cvpr-2017
https://github.com/jswulff/mrflow

A Generative Model of People in Clothing
2017-06-15
We provide an image-based generative model of people in clothing for the full body. The training dataset is built on top of Chictopia10K. We provide processed annotations as well as the SMPL body model fit to the images. We also provide our trained models for download.
http://files.is.tuebingen.mpg.de/classner/gp/
https://github.com/classner/generating_people

Slow Flow: Exploiting High-Speed Cameras for Accurate and Diverse Optical Flow Reference Data
2017-06-01
Existing optical flow datasets are limited in size and variability due to the difficulty of capturing dense ground truth. In this paper, we tackle this problem by tracking pixels through densely sampled space-time volumes recorded with a high-speed video camera. Our model exploits the linearity of small motions and reasons about occlusions from multiple frames. Using our technique, we are able to establish accurate reference flow fields outside the laboratory in natural environments. Besides, we show how our predictions can be used to augment the input images with realistic motion blur. We demonstrate the quality of the produced flow fields on synthetic and real-world datasets. Finally, we collect a novel challenging optical flow dataset by applying our technique on data from a high-speed camera and analyze the performance of the state-of-the-art in optical flow under various levels of motion blur. Includes high-frame-rate version of the Sintel dataset.
http://www.cvlibs.net/projects/slow_flow/
https://github.com/autonomousvision/slow_flow
Scan Manager
2017-04-07
A web application for being able to manage the increasing amount of body scans.
python django celery rabbitmq

SPyNet: Optical Flow Estimation using a Spatial Pyramid Network
2017-04-01
We learn to compute optical flow by combining a classical spatial-pyramid formulation with deep learning. This estimates large motions in a coarse-to-fine approach by warping one image of a pair at each pyramid level by the current flow estimate and computing an update to the flow. Instead of the standard minimization of an objective function at each pyramid level, we train one deep network per level to compute the flow update. Check the website for updates; we provide code for the original SypNet as well as an end-to-end trainable version.
http://spynet.is.tue.mpg.de/
https://github.com/anuragranj/spynet

Capturing Hand-Object Interaction and Reconstruction of Manipulated Objects
2017-01-17
Webpages for the GCPR 2013, GCPR 2014, ICCV 2015, IJCV 2016, ECCVw 2016 papers. The data contains: (IJCV 2016, GCPR 2014) annotated RGB-D and multicamera-RGB dataset of one or two hands interacting with each other and/or with a rigid or an articulated object, (ICCV 2015) RGB-D dataset of a hand rotating a rigid object for 3d scanning, (GCPR 2013) synthetic dataset of two hands interacting with each other, (ECCVw 2016) RGB-D dataset of an object under manipulation.

SMPLify: 3D human pose and shape estimation from a single image
2016-10-08
Given a single image, extract the 3D SMPL pose and shape parameters. We provide a Python demo code needed to run SMPLify. We also provide results from the ECCV paper for comparison. For all the datasets we used (LSP, HumanEva-I, Human3.6M) we provide the detected joints and our results as SMPL model parameters and as a mesh (vertices and faces). The code package includes an example script showing how to load results. Please see the README in the code package and the FAQ.
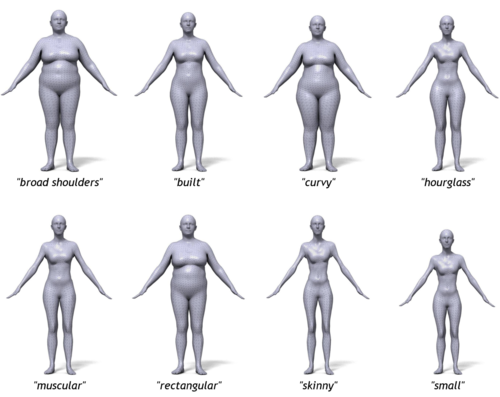
BodyTalk: Tool that relates 3D body shape to words
2016-07-24
This website provides a tool to explore 3D body shape and linguistic descriptions of shape. We provide a set of shape sliders and linguistic sliders that can be used to change body shape. This allows you to explore how people think about body shape and how shape and adjectives are correlated.

Semantic Optical Flow
2016-06-01
Data and code necessary to reproduce results from the CVPR 2016 paper on semantic optical flow. Semantic scene segmentation enables different flow models to be used in different regions and then composed using a locally layered approach.
https://ps.is.tuebingen.mpg.de/publications/sevilla-cvpr-2016
https://ps.is.tuebingen.mpg.de/uploads_file/attachment/attachment/281/semantic_flow_code_release.zip

Video segmentation via object flow
2016-06-01
Matlab implementation of the paper Video Segmentation via Object Flow Yi-Hsuan Tsai, Ming-Hsuan Yang and Michael J. Black IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.

SMPL: A skinned multi-person linear body model
2015-12-15
SMPL is like a PDF format for 3D bodies. It is a realistic 3D model of the human body that is based on blend skinning and blend shapes that is learned from thousands of 3D body scans. It is fully portable, works with many existing game engines and is useful for computer vision. This site provides resources to learn about SMPL, including example FBX files with animated SMPL models, and code for using SMPL in Python, Maya and Unity. The Python code shows how to use SMPL in computer vision problems. Maya and Unity scripts help set up the model for animation in these 3D environments. We provide regular updates with new features such as dynamic blend shapes, animated mocap sequences, and model improvements.

MoSh: Motion and Shape Capture from Sparse Markers
2015-11-14
The original MoSh dataset is available as well as code for the latest MoSh++ method. Marker-based motion capture (mocap) is widely criticized as producing lifeless animations. MoSh (Motion and Shape capture), automatically extracts detail present in the original mocap maker data. MoSh estimates body shape and pose together using sparse marker data by exploiting a parametric model of the human body. The dataset contains: 1) The original .c3d files with MOCAP marker-data. 2) Estimated 3D shape meshes. 3) 3D scans from a high resolution scanner for comparison. The code is the latest MoSh++ method that estimates SMPL-X bodies (see the AMASS paper for details).
http://mosh.is.tue.mpg.de/
https://github.com/nghorbani/moshpp
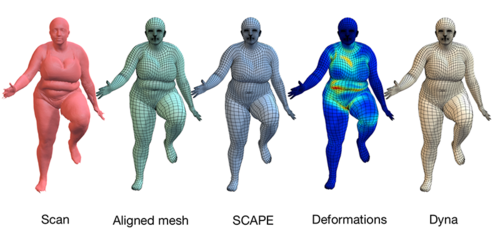
Dyna: 4D meshes of dynamic human soft tissue motion
2015-08-15
To look human, digital full-body avatars need to have soft tissue deformations like those of real people. Current methods for physics simulation of soft tissue lack realism, are computationally expensive, or are hard to tune. Learning soft tissue motion from example, however, has been limited by the lack of dense, high-resolution, training data. We address this using a 4D capture system and a method for accurately registering 3D scans across time to a template mesh. Using over 40,000 scans of ten subjects, we compute how soft tissue motion causes mesh triangles to deform relative to a base 3D body model and learn a low-dimensional linear subspace approximating this soft-tissue deformation. This dataset contains all 40,000 training meshes which have the same mesh topology. See the Dynamic FAUST dataset for the raw scans and improved registered meshes.

Pose-Conditioned Joint Angle Limits for 3D Human Pose Reconstruction (code and data)
2015-06-08
This release contains code and data. Most mocap datasets are too small or to constrained to capture the full range of human motions. In particular, they are too small to explore joint angle limits. Here we provide a mocap dataset in which the subjects are gymnasts who are able to explore a wide range of human poses. The dataset allows one to develop pose priors that obey these limits and to model how these joint limits actually vary with pose. We include code to learn joint angle limits and to estimate 3D pose from 2D joint locations.

KITTI 2015: Stereo, Flow, and Scene Flow Benchmark
2015-06-01
KITTI is one of the most popular datasets for evaluation of vision algorithms, particuarly in the context of street scenes and autonomous driving. The stereo 2015 / flow 2015 / scene flow 2015 benchmark consists of 200 training scenes and 200 test scenes (4 color images per scene, saved in loss less png format). Compared to the stereo 2012 and flow 2012 benchmarks, it comprises dynamic scenes for which the ground truth has been established in a semi-automatic process.
http://www.cvlibs.net/datasets/kitti/eval_scene_flow.php?benchmark=flow
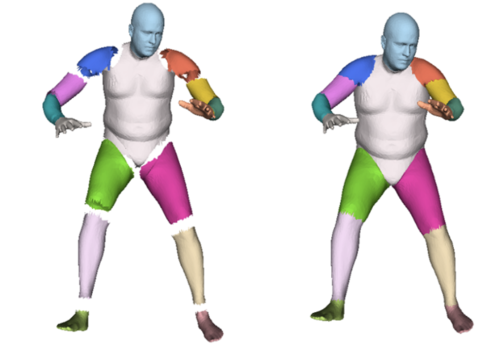
The Stitched Puppet: A Graphical Model of 3D Human Shape and Pose
2015-06-01
The Stitched Puppet (SP) is a realistic part-based 3D body model of the human body. It offers the best features of part-based body models used in Computer Vision and statistical body models used in Computer Graphics. The release includes data and code to fit the SP model to 3D scans.
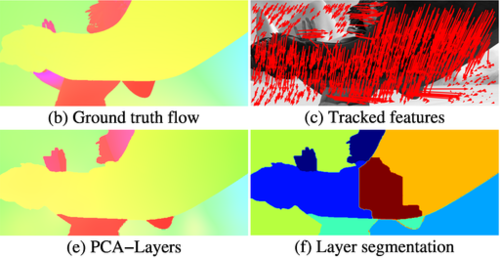
PCA-Flow: Fast, approximate optical flow computation
2015-06-01
This software package contains two algorithms for the computation of optical flow, as described in Wulff & Black, "Efficient Sparse-to-Dense Optical Flow Estimation using a Learned Basis and Layers" (CVPR 2015). PCA-Flow computes approximate optical flow extremely quickly, by making the assumption that optical flow lies on a low-dimensional subspace. PCA-Layers extends this to a layered model to increase accuracy, especially at boundaries. It is the most accurate layered model on the MPI Sintel dataset.

OpenDR: An open differentiable renderer
2014-09-01
The OpenDR, is the first open source differentiable renderer. It provides a simple Python interface for defining an objective function with a forward generative process and then automatically differentiating and optimizing this. OpenDR allows for quick design and testing of generative models in computer vision. The code provides examples. OpenDR has been widely use.
https://github.com/mattloper/opendr/wiki
https://github.com/mattloper/opendr
FAUST dataset: High-resolution 3D scans with ground truth correspondence
2014-06-15
FAUST contains 300 real, high-resolution human scans of 10 different subjects in 30 different poses, with automatically computed ground-truth correspondences. We provide a training set with scans and ground truth correspondence. We also provide a separate test set of scans with an evaluation website that compares results of mesh correspondence.
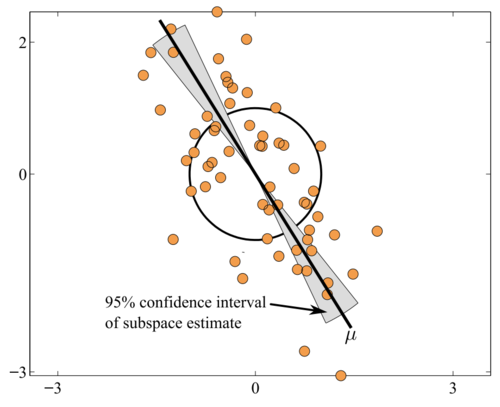
Robust and scalable PCA using Grassmann averages
2014-06-01
The Grassmann Averages PCA is a method for extracting the principal components from a sets of vectors, with the nice following properties: 1) it is of linear complexity wrt. the dimension of the vectors and the size of the data, which makes the method highly scalable, 2) It is more robust to outliers than PCA in the sense that it minimizes an L1 norm instead of the L2 norm of the standard PCA. It comes with two variants: 1) the standard computation, that coincides with the PCA for normally distributed data, also referred to as the GA, 2) a trimmed variant, that is more robust to outliers, referred to the TGA. We provide implementations for the Grassmann Average, the Trimmed Grassmann Average, and the Grassmann Median. The simplest is the Matlab implementation used in the CVPR 2014 paper, but we also provide a faster C++ implementation, which can be used either directly from C++ or through a Matlab wrapper interface. The repository contains the following:
- a C++ multi-threaded implementation of the GA and TGA
- a C++ multi-threaded implementation of the EM-PCA (for comparisons)
- binaries that computes the GA, TGA and EM-PCA on a set of images (frames of a video)
- Matlab bindings
- Documentation of the C++ API
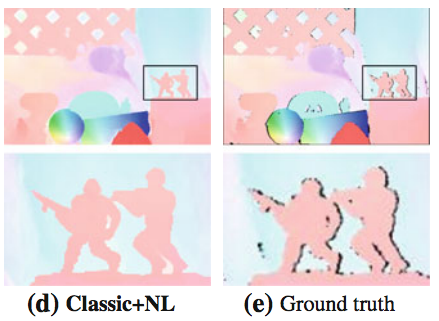
Secrets of Optical Flow: Code for various methods
2014-06-01
Matlab code for robust optical flow -- Classic++ and Classic-NL -- as described in the IJCV paper "A Quantitative Analysis of Current Practices in Optical Flow Estimation and the Principles behind Them". This code is widely used as a baseline and starting point for "classical" flow methods. Matlab version of the "Black and Anandan" robust flow method: https://deqings.github.io/public_files/ba.zip Matlab version of "Horn and Schunck": https://deqings.github.io/public_files/hs.zip Original implementation from CVPR'2010 paper: https://deqings.github.io/public_files/cvpr10_flow_code.zip

JHMDB: Joint-annotated Human Motion Data Base
2013-12-01
A fully annotated data set for human actions and human poses. It is based on the HMDB human motion dataset but includes optical flow on the person, the segmentation of the person, joint locations, action labels, and meta data.
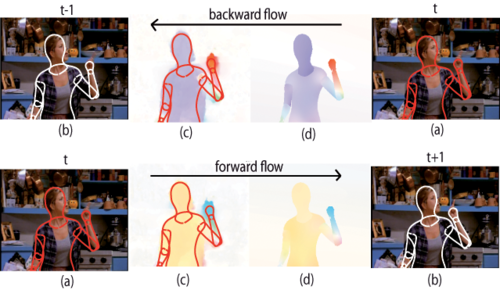
Flowing Puppets
2013-12-01
Code for ICCV'13 paper on "Estimating Human Pose with Flowing Puppets". This addresses the problem of upper-body human pose estimation in uncontrolled monocular video sequences, without manual initialization. The "flowing puppets" model provide integrates image evidence across frames to improve pose inference. We provide the code used for the experiments in the paper. We also provide the "puppet flow" annotation tool.
https://ps.is.tuebingen.mpg.de/research_projects/flowing-puppets
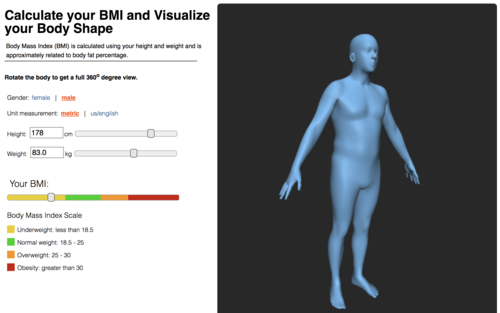
BMI Visualizer
2013-06-01
This website helps people understand body mass index through a novel visualization of 3D body shape. Enter height and weight to see a 3D body shape with these properties and see the corresponding BMI. Move a slider to change BMI and see how body shape changes.

The KITTI Dataset
2013-06-01
The KITTI dataset is the de-facto standard for developing and testing computer vision algorithms for real-world autonomous driving scenarios and more.
http://www.cvlibs.net/datasets/kitti/

Sintel Optical Flow Dataset and Benchmark
2012-10-15
The MPI Sintel Dataset is one of the most widely used datasets for training and evaluating optical flow algorithms. It is the first synthetic dataset to achieve wide use because of it well represents natural scenes and motions. It is also extremely challenging and current methods have still not fully "solved" the problem of flow estimation for Sintel. Sintel is designed to encourage research on long-range motion, motion blur, multi-frame analysis, non-rigid motion. Algorithms are evaluated on held-out test data and results are displayed for comparison. The dataset contains flow fields, motion boundaries, unmatched regions, and image sequences. The image sequences are rendered with different levels of difficulty. We also provide ground truth depth, stereo, and camera motions. Sintel is an open source animated short film produced by Ton Roosendaal and the Blender Foundation. Here we have modified the film in many ways to make it useful for optical flow evaluation.
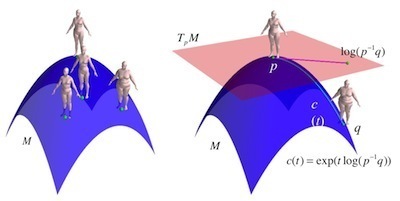
Lie Bodies
2012-10-01
This code supports the core representation needed for Lie Bodies as described in Freifeld and Black, ECCV 2012. Currently this is only a partial version of what is presented in the paper. The code takes pairs of triangles and computes the "Q" matrices and the corresponding (R,A,S) decompositions that are the foundation of Lie Bodies (see paper for details).
https://github.com/freifeld/triangledeformations
body shape scape manifold statistics deformation pose shape Lie algebra
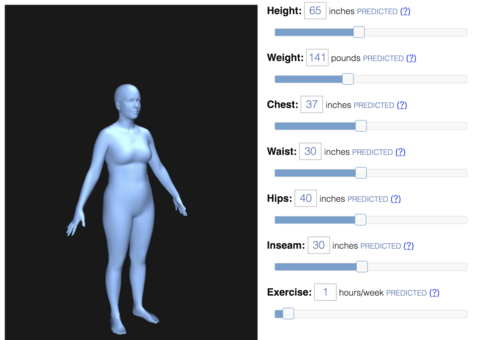
Body Shape Visualizer
2011-06-01
This web-based tool lets users enter information about body measurements (height, waist, inseam, etc) and visualize a 3D body shape that corresponds to these measurements.

Middlebury Optical Flow Dataset and Benchmark
2011-03-13
The Middlebury flow dataset has been a de-facto standard in the field since 2007. The dataset introduced several innovations. It is the first dataset to contain real image sequences with independent motions, and ground truth optical flow. Second, it provides realistically rendered synthetic scenes with ground truth flow. It also includes a frame interpolation task using real video sequences. While, by today's standards, the dataset is small and the sequences somewhat simple, it remains a useful tool for evaluating the generality of optical flow methods.

HumanEva datasets I and II
2010-03-01
HumanEva: Synchronized video and motion capture dataset and baseline algorithm for evaluation of articulated human motion. This is the repository for the widely use HumanEva dataset. This was the first dataset to include mutii-camera video capture of people with ground truth 3D human pose. It established the quantitative evaluation of human pose estimation using well-defined metrics in 2D and 3D. The dataset was developed at Brown University and is hosted by MPI.

Archival Image sequences
1996-10-13
This is a collection of images sequences used in the 1990's and early 2000's. It includes the Yosemite sequences, Flower garden, and several others.
https://files.is.tue.mpg.de/black/Brown/Sequences/oldSequences.html

Robust dense optical flow estimation
1992-10-01
This is the original C implementation of the "Black and Anandan" optical flow algorithm. For a Matlab version that is written by Deqing Sun and much better see: https://deqings.github.io/public_files/ba.zip
Robust area-based optical flow estimation
This is the original C version of the robust area-based flow code from Michael Black's thesis.