4 results
(View BibTeX file of all listed publications)
2022

Reconstructing Expressive 3D Humans from RGB Images
ETH Zurich, Max Planck Institute for Intelligent Systems and ETH Zurich, December 2022 (thesis)
To interact with our environment, we need to adapt our body posture
and grasp objects with our hands. During a conversation our facial expressions
and hand gestures convey important non-verbal cues about our
emotional state and intentions towards our fellow speakers. Thus, modeling
and capturing 3D full-body shape and pose, hand articulation and facial
expressions are necessary to create realistic human avatars for augmented
and virtual reality. This is a complex task, due to the large number of
degrees of freedom for articulation, body shape variance, occlusions from
objects and self-occlusions from body parts, e.g. crossing our hands, and
subject appearance. The community has thus far relied on expensive and
cumbersome equipment, such as multi-view cameras or motion capture
markers, to capture the 3D human body. While this approach is effective,
it is limited to a small number of subjects and indoor scenarios. Using
monocular RGB cameras would greatly simplify the avatar creation process,
thanks to their lower cost and ease of use. These advantages come at a price
though, since RGB capture methods need to deal with occlusions, perspective
ambiguity and large variations in subject appearance, in addition to
all the challenges posed by full-body capture. In an attempt to simplify the
problem, researchers generally adopt a divide-and-conquer strategy, estimating
the body, face and hands with distinct methods using part-specific
datasets and benchmarks. However, the hands and face constrain the body
and vice-versa, e.g. the position of the wrist depends on the elbow, shoulder,
etc.; the divide-and-conquer approach can not utilize this constraint.
In this thesis, we aim to reconstruct the full 3D human body, using only
readily accessible monocular RGB images. In a first step, we introduce a
parametric 3D body model, called SMPL-X, that can represent full-body
shape and pose, hand articulation and facial expression. Next, we present
an iterative optimization method, named SMPLify-X, that fits SMPL-X to
2D image keypoints. While SMPLify-X can produce plausible results if
the 2D observations are sufficiently reliable, it is slow and susceptible
to initialization. To overcome these limitations, we introduce ExPose, a
neural network regressor, that predicts SMPL-X parameters from an image
using body-driven attention, i.e. by zooming in on the hands and face,
after predicting the body. From the zoomed-in part images, dedicated
part networks predict the hand and face parameters. ExPose combines
the independent body, hand, and face estimates by trusting them equally.
This approach though does not fully exploit the correlation between parts
and fails in the presence of challenges such as occlusion or motion blur.
Thus, we need a better mechanism to aggregate information from the full
body and part images. PIXIE uses neural networks called moderators that
learn to fuse information from these two image sets before predicting the
final part parameters. Overall, the addition of the hands and face leads to
noticeably more natural and expressive reconstructions.
Creating high fidelity avatars from RGB images requires accurate estimation
of 3D body shape. Although existing methods are effective at
predicting body pose, they struggle with body shape. We identify the lack
of proper training data as the cause. To overcome this obstacle, we propose
to collect internet images from fashion models websites, together with
anthropometric measurements. At the same time, we ask human annotators
to rate images and meshes according to a pre-defined set of linguistic attributes.
We then define mappings between measurements, linguistic shape
attributes and 3D body shape. Equipped with these mappings, we train a
neural network regressor, SHAPY, that predicts accurate 3D body shapes
from a single RGB image. We observe that existing 3D shape benchmarks
lack subject variety and/or ground-truth shape. Thus, we introduce a new
benchmark, Human Bodies in the Wild (HBW), which contains images of
humans and their corresponding 3D ground-truth body shape. SHAPY
shows how we can overcome the lack of in-the-wild images with 3D shape
annotations through easy-to-obtain anthropometric measurements and linguistic
shape attributes.
Regressors that estimate 3D model parameters are robust and accurate,
but often fail to tightly fit the observations. Optimization-based approaches
tightly fit the data, by minimizing an energy function composed of a data
term that penalizes deviations from the observations and priors that encode
our knowledge of the problem. Finding the balance between these terms
and implementing a performant version of the solver is a time-consuming
and non-trivial task. Machine-learned continuous optimizers combine the
benefits of both regression and optimization approaches. They learn the
priors directly from data, avoiding the need for hand-crafted heuristics and
loss term balancing, and benefit from optimized neural network frameworks
for fast inference. Inspired from the classic Levenberg-Marquardt
algorithm, we propose a neural optimizer that outperforms classic optimization,
regression and hybrid optimization-regression approaches. Our
proposed update rule uses a weighted combination of gradient descent
and a network-predicted update. To show the versatility of the proposed
method, we apply it on three other problems, namely full body estimation
from (i) 2D keypoints, (ii) head and hand location from a head-mounted
device and (iii) face tracking from dense 2D landmarks. Our method can
easily be applied to new model fitting problems and offers a competitive
alternative to well-tuned traditional model fitting pipelines, both in terms
of accuracy and speed.
To summarize, we propose a new and richer representation of the human
body, SMPL-X, that is able to jointly model the 3D human body pose
and shape, facial expressions and hand articulation. We propose methods,
SMPLify-X, ExPose and PIXIE that estimate SMPL-X parameters from
monocular RGB images, progressively improving the accuracy and realism
of the predictions. To further improve reconstruction fidelity, we demonstrate
how we can use easy-to-collect internet data and human annotations
to overcome the lack of 3D shape data and train a model, SHAPY, that
predicts accurate 3D body shape from a single RGB image. Finally, we
propose a flexible learnable update rule for parametric human model fitting
that outperforms both classic optimization and neural network approaches.
This approach is easily applicable to a variety of problems, unlocking new
applications in AR/VR scenarios.
2014

Learning People Detectors for Tracking in Crowded Scenes.
Tang, S., Andriluka, M., Milan, A., Schindler, K., Roth, S., Schiele, B.
2014, Scene Understanding Workshop (SUNw, CVPR workshop) (unpublished)
2013
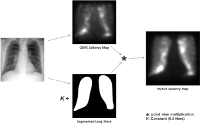
A Study of X-Ray Image Perception for Pneumoconiosis Detection
IIIT-Hyderabad, Hyderabad, India, January 2013 (mastersthesis)
Pneumoconiosis is an occupational lung disease caused by the inhalation of industrial dust. Despite the increasing safety measures and better work place environments, pneumoconiosis is deemed to be the most common occupational disease in the developing countries like India and China. Screening and assessment of this disease is done through radiological observation of chest x-rays. Several studies have shown the significant inter and intra reader observer variation in the diagnosis of this disease, showing the complexity of the task and importance of the expertise in diagnosis.
The present study is aimed at understanding the perceptual and cognitive factors affecting the reading of chest x-rays of pneumoconiosis patients. Understanding these factors helps in developing better image acquisition systems, better training regimen for radiologists and development of better computer aided diagnostic (CAD) systems. We used an eye tracking experiment to study the various factors affecting the assessment of this diffused lung disease. Specifically, we aimed at understanding the role of expertize, contralateral symmetric (CS) information present in chest x-rays on the diagnosis and the eye movements of the observers. We also studied the inter and intra observer fixation consistency along with the role of anatomical and bottom up saliency features in attracting the gaze of observers of different expertize levels, to get better insights into the effect of bottom up and top down visual saliency on the eye movements of observers.
The experiment is conducted in a room dedicated to eye tracking experiments. Participants consisting of novices (3), medical students (12), residents (4) and staff radiologists (4) were presented with good quality PA chest X-rays, and were asked to give profusion ratings for each of the 6 lung zones. Image set consisting of 17 normal full chest x-rays and 16 single lung images are shown to the participants in random order. Time of the diagnosis and the eye movements are also recorded using a remote head free eye tracker.
Results indicated that Expertise and CS play important roles in the diagnosis of pneumoconiosis. Novices and medical students are slow and inefficient whereas, residents and staff are quick and efficient. A key finding of our study is that the presence of CS information alone does not help improve diagnosis as much as learning how to use the information. This learning appears to be gained from focused training and years of experience. Hence, good training for radiologists and careful observation of each lung zone may improve the quality of diagnostic results. For residents, the eye scanning strategies play an important role in using the CS information present in chest radiographs; however, in staff radiologists, peripheral vision or higher-level cognitive processes seems to play role in using the CS information.
There is a reasonably good inter and intra observer fixation consistency suggesting the use of similar viewing strategies. Experience is helping the observers to develop new visual strategies based on the image content so that they can quickly and efficiently assess the disease level. First few fixations seem to be playing an important role in choosing the visual strategy, appropriate for the given image.
Both inter-rib and rib regions are given equal importance by the observers. Despite reading of chest x-rays being highly task dependent, bottom up saliency is shown to have played an important role in attracting the fixations of the observers. This role of bottom up saliency seems to be more in lower expertize groups compared to that of higher expertize groups. Both bottom up and top down influence of visual fixations seems to change with time. The relative role of top down and bottom up influences of visual attention is still not completely understood and it remains the part of future work.
Based on our experimental results, we have developed an extended saliency model by combining the bottom up saliency and the saliency of lung regions in a chest x-ray. This new saliency model performed significantly better than bottom-up saliency in predicting the gaze of the observers in our experiment. Even though, the model is a simple combination of bottom-up saliency maps and segmented lung masks, this demonstrates that even basic models using simple image features can predict the fixations of the observers to a good accuracy.
Experimental analysis suggested that the factors affecting the reading of chest x-rays of pneumoconiosis are complex and varied. A good understanding of these factors definitely helps in the development of better radiological screening of pneumoconiosis through improved training and also through the use of improved CAD tools. The presented work is an attempt to get insights into what these factors are and how they modify the behavior of the observers.
2012
An Analysis of Successful Approaches to Human Pose Estimation
An Analysis of Successful Approaches to Human Pose Estimation, University of Augsburg, University of Augsburg, May 2012 (mastersthesis)
The field of Human Pose Estimation is developing fast and lately leaped forward
with the release of the Kinect system. That system reaches a very good perfor-
mance for pose estimation using 3D scene information, however pose estimation
from 2D color images is not solved reliably yet. There is a vast amount of pub-
lications trying to reach this aim, but no compilation of important methods and
solution strategies. The aim of this thesis is to fill this gap: it gives an introductory
overview over important techniques by analyzing four current (2012) publications
in detail. They are chosen such, that during their analysis many frequently used
techniques for Human Pose Estimation can be explained. The thesis includes two
introductory chapters with a definition of Human Pose Estimation and exploration
of the main difficulties, as well as a detailed explanation of frequently used methods.
A final chapter presents some ideas on how parts of the analyzed approaches can
be recombined and shows some open questions that can be tackled in future work.
The thesis is therefore a good entry point to the field of Human Pose Estimation
and enables the reader to get an impression of the current state-of-the-art.