2022

Reconstructing Expressive 3D Humans from RGB Images


2014
Model transport: towards scalable transfer learning on manifolds - supplemental material
Freifeld, O., Hauberg, S., Black, M. J.
(9), April 2014 (techreport)

RoCKIn@Work in a Nutshell
Ahmad, A., Amigoni, A., Awaad, I., Berghofer, J., Bischoff, R., Bonarini, A., Dwiputra, R., Fontana, G., Hegger, F., Hochgeschwender, N., Iocchi, L., Kraetzschmar, G., Lima, P., Matteucci, M., Nardi, D., Schiaffonati, V., Schneider, S.
(FP7-ICT-601012 Revision 1.2), RoCKIn - Robot Competitions Kick Innovation in Cognitive Systems and Robotics, March 2014 (techreport)
RoCKIn@Home in a Nutshell
Ahmad, A., Amigoni, F., Awaad, I., Berghofer, J., Bischoff, R., Bonarini, A., Dwiputra, R., Fontana, G., Hegger, F., Hochgeschwender, N., Iocchi, L., Kraetzschmar, G., Lima, P., Matteucci, M., Nardi, D., Schneider, S.
(FP7-ICT-601012 Revision 0.8), RoCKIn - Robot Competitions Kick Innovation in Cognitive Systems and Robotics, March 2014 (techreport)
2013

Puppet Flow
D2.1.4 RoCKIn@Work - Innovation in Mobile Industrial Manipulation Competition Design, Rule Book, and Scenario Construction
Ahmad, A., Awaad, I., Amigoni, F., Berghofer, J., Bischoff, R., Bonarini, A., Dwiputra, R., Hegger, F., Hochgeschwender, N., Iocchi, L., Kraetzschmar, G., Lima, P., Matteucci, M., Nardi, D., Schneider, S.
(FP7-ICT-601012 Revision 0.7), RoCKIn - Robot Competitions Kick Innovation in Cognitive Systems and Robotics, sep 2013 (techreport)
D2.1.1 RoCKIn@Home - A Competition for Domestic Service Robots Competition Design, Rule Book, and Scenario Construction
Ahmad, A., Awaad, I., Amigoni, F., Berghofer, J., Bischoff, R., Bonarini, A., Dwiputra, R., Hegger, F., Hochgeschwender, N., Iocchi, L., Kraetzschmar, G., Lima, P., Matteucci, M., Nardi, D., Schneider, S.
(FP7-ICT-601012 Revision 0.7), RoCKIn - Robot Competitions Kick Innovation in Cognitive Systems and Robotics, sep 2013 (techreport)
D1.1 Specification of General Features of Scenarios and Robots for Benchmarking Through Competitions
Ahmad, A., Awaad, I., Amigoni, F., Berghofer, J., Bischoff, R., Bonarini, A., Dwiputra, R., Fontana, G., Hegger, F., Hochgeschwender, N., Iocchi, L., Kraetzschmar, G., Lima, P., Matteucci, M., Nardi, D., Schiaffonati, V., Schneider, S.
(FP7-ICT-601012 Revision 1.0), RoCKIn - Robot Competitions Kick Innovation in Cognitive Systems and Robotics, July 2013 (techreport)
SocRob-MSL 2013 Team Description Paper for Middle Sized League
Messias, J., Ahmad, A., Reis, J., Serafim, M., Lima, P.
17th Annual RoboCup International Symposium 2013, July 2013 (techreport)

A Quantitative Analysis of Current Practices in Optical Flow Estimation and the Principles Behind Them
Sun, D., Roth, S., Black, M. J.
(CS-10-03), Brown University, Department of Computer Science, January 2013 (techreport)
2012
Coregistration: Supplemental Material

Lie Bodies: A Manifold Representation of 3D Human Shape. Supplemental Material

MPI-Sintel Optical Flow Benchmark: Supplemental Material
HUMIM Software for Articulated Tracking
Soren Hauberg, Kim S. Pedersen
(01/2012), Department of Computer Science, University of Copenhagen, January 2012 (techreport)
A geometric framework for statistics on trees
Aasa Feragen, Mads Nielsen, Soren Hauberg, Pechin Lo, Marleen de Bruijne, Francois Lauze
(11/02), Department of Computer Science, University of Copenhagen, January 2012 (techreport)
2011
ISocRob-MSL 2011 Team Description Paper for Middle Sized League
Messias, J., Ahmad, A., Reis, J., Sousa, J., Lima, P.
15th Annual RoboCup International Symposium 2011, July 2011 (techreport)
2010
ImageFlow: Streaming Image Search
Jampani, V., Ramos, G., Drucker, S.
MSR-TR-2010-148, Microsoft Research, Redmond, 2010 (techreport)
2009
ISocRob-MSL 2009 Team Description Paper for Middle Sized League
Lima, P., Santos, J., Estilita, J., Barbosa, M., Ahmad, A., Carreira, J.
13th Annual RoboCup International Symposium 2009, July 2009 (techreport)
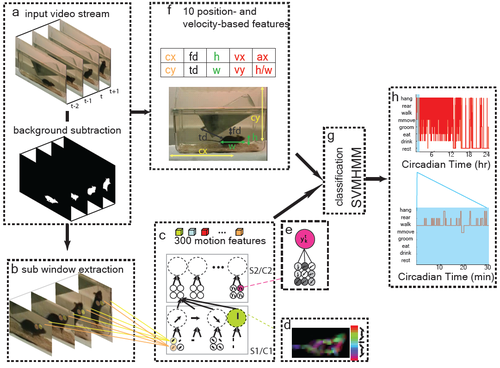
Automatic recognition of rodent behavior: A tool for systematic phenotypic analysis
Serre, T.*, Jhuang, H*., Garrote, E., Poggio, T., Steele, A.
CBCL paper #283/MIT-CSAIL-TR #2009-052., MIT, 2009 (techreport)
Incremental nonparametric Bayesian regression
Wood, F., Grollman, D. H., Heller, K. A., Jenkins, O. C., Black, M. J.
(CS-08-07), Brown University, Department of Computer Science, 2008 (techreport)
2007

Denoising archival films using a learned Bayesian model
Moldovan, T. M., Roth, S., Black, M. J.
(CS-07-03), Brown University, Department of Computer Science, 2007 (techreport)
2006
Implicit Wiener Series, Part II: Regularised estimation

HumanEva: Synchronized video and motion capture dataset for evaluation of articulated human motion
Sigal, L., Black, M. J.
(CS-06-08), Brown University, Department of Computer Science, 2006 (techreport)
1996

Mixture Models for Image Representation
Jepson, A., Black, M.
PRECARN ARK Project Technical Report ARK96-PUB-54, March 1996 (techreport)