2024
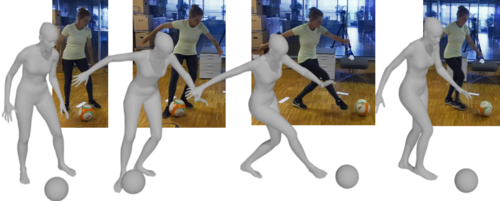
InterCap: Joint Markerless 3D Tracking of Humans and Objects in Interaction from Multi-view RGB-D Images
Huang, Y., Taheri, O., Black, M. J., Tzionas, D.
International Journal of Computer Vision (IJCV), 2024 (article)

HMP: Hand Motion Priors for Pose and Shape Estimation from Video
2023

FLARE: Fast learning of Animatable and Relightable Mesh Avatars
Bharadwaj, S., Zheng, Y., Hilliges, O., Black, M. J., Abrevaya, V. F.
ACM Transactions on Graphics, 42(6):204:1-204:15, December 2023 (article) Accepted
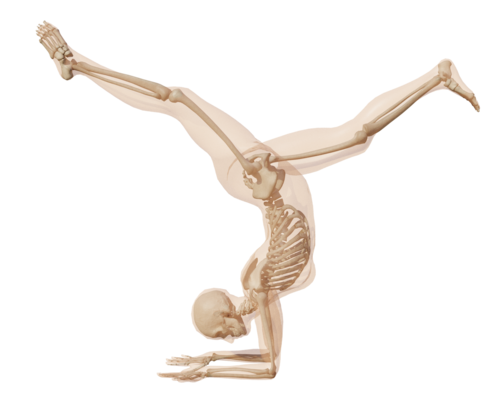
From Skin to Skeleton: Towards Biomechanically Accurate 3D Digital Humans
(Honorable Mention for Best Paper)
Keller, M., Werling, K., Shin, S., Delp, S., Pujades, S., Liu, C. K., Black, M. J.
ACM Transaction on Graphics (ToG), 42(6):253:1-253:15, December 2023 (article)

BARC: Breed-Augmented Regression Using Classification for 3D Dog Reconstruction from Images
Rueegg, N., Zuffi, S., Schindler, K., Black, M. J.
Int. J. of Comp. Vis. (IJCV), 131(8):1964–1979, August 2023 (article)

Virtual Reality Exposure to a Healthy Weight Body Is a Promising Adjunct Treatment for Anorexia Nervosa
Behrens, S. C., Tesch, J., Sun, P. J., Starke, S., Black, M. J., Schneider, H., Pruccoli, J., Zipfel, S., Giel, K. E.
Psychotherapy and Psychosomatics, 92(3):170-179, June 2023 (article)
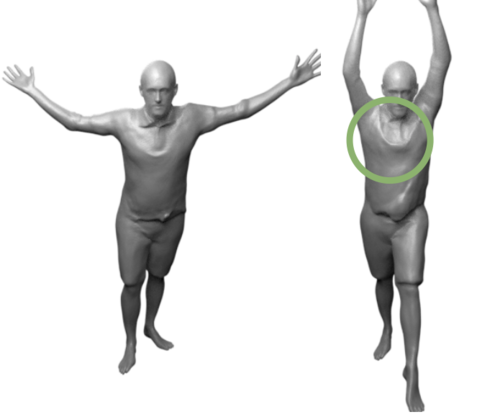
Fast-SNARF: A Fast Deformer for Articulated Neural Fields
Chen, X., Jiang, T., Song, J., Rietmann, M., Geiger, A., Black, M. J., Hilliges, O.
IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), pages: 1-15, April 2023 (article)

SmartMocap: Joint Estimation of Human and Camera Motion Using Uncalibrated RGB Cameras
Saini, N., Huang, C. P., Black, M. J., Ahmad, A.
IEEE Robotics and Automation Letters, 8(6):3206-3213, 2023 (article)
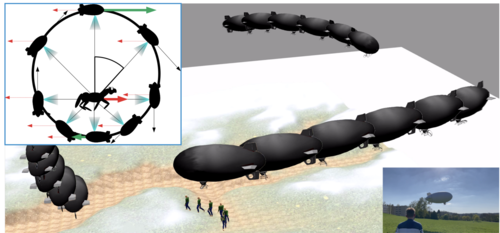
Viewpoint-Driven Formation Control of Airships for Cooperative Target Tracking
Price, E., Black, M. J., Ahmad, A.
IEEE Robotics and Automation Letters, 8(6):3653-3660, 2023 (article)
2022
How immersive virtual reality can become a key tool to advance research and psychotherapy of eating and weight disorders
Behrens, S. C., Streuber, S., Keizer, A., Giel, K. E.
Frontiers in Psychiatry, 13, pages: 1011620, November 2022 (article)

iRotate: Active visual SLAM for omnidirectional robots
Bonetto, E., Goldschmid, P., Pabst, M., Black, M. J., Ahmad, A.
Robotics and Autonomous Systems, 154, pages: 104102, Elsevier, August 2022 (article)

AirPose: Multi-View Fusion Network for Aerial 3D Human Pose and Shape Estimation
Saini, N., Bonetto, E., Price, E., Ahmad, A., Black, M. J.
IEEE Robotics and Automation Letters, 7(2):4805-4812, IEEE, April 2022, Also accepted and presented in the 2022 IEEE International Conference on Robotics and Automation (ICRA) (article)

Physical activity improves body image of sedentary adults. Exploring the roles of interoception and affective response
Srismith, D., Dierkes, K., Zipfel, S., Thiel, A., Sudeck, G., Giel, K. E., Behrens, S. C.
Current Psychology, Springer, 2022 (article) Accepted
2021
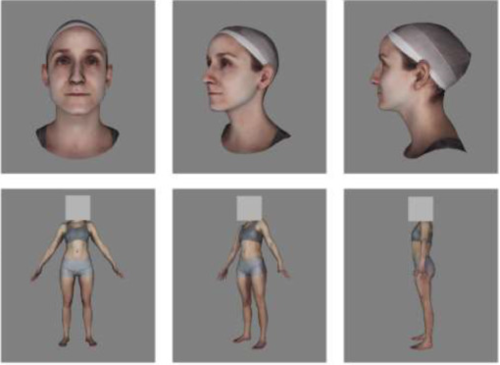
The neural coding of face and body orientation in occipitotemporal cortex
Foster, C., Zhao, M., Bolkart, T., Black, M. J., Bartels, A., Bülthoff, I.
NeuroImage, 246, pages: 118783, December 2021 (article)
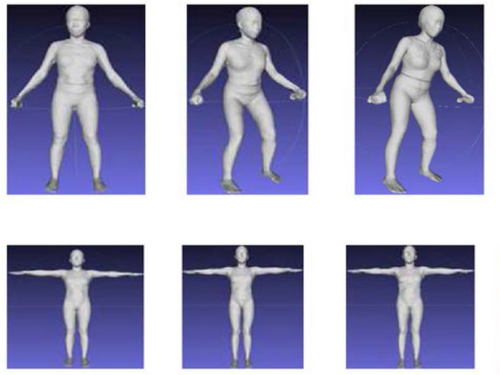
A pose-independent method for accurate and precise body composition from 3D optical scans
Wong, M. C., Ng, B. K., Tian, I., Sobhiyeh, S., Pagano, I., Dechenaud, M., Kennedy, S. F., Liu, Y. E., Kelly, N., Chow, D., Garber, A. K., Maskarinec, G., Pujades, S., Black, M. J., Curless, B., Heymsfield, S. B., Shepherd, J. A.
Obesity, 29(11):1835-1847, Wiley, November 2021 (article)
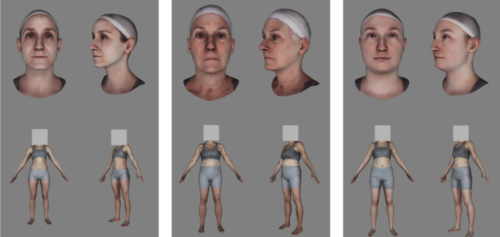
Separated and overlapping neural coding of face and body identity
Foster, C., Zhao, M., Bolkart, T., Black, M. J., Bartels, A., Bülthoff, I.
Human Brain Mapping, 42(13):4242-4260, September 2021 (article)
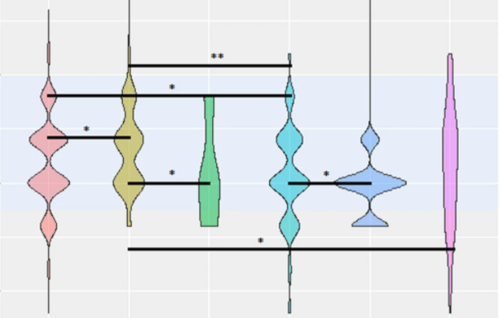
The role of sexual orientation in the relationships between body perception, body weight dissatisfaction, physical comparison, and eating psychopathology in the cisgender population
Meneguzzo, P., Collantoni, E., Bonello, E., Vergine, M., Behrens, S. C., Tenconi, E., Favaro, A.
Eating and Weight Disorders - Studies on Anorexia, Bulimia and Obesity , 26(6):1985-2000, Springer, August 2021 (article)

Learning an Animatable Detailed 3D Face Model from In-the-Wild Images
Feng, Y., Feng, H., Black, M. J., Bolkart, T.
ACM Transactions on Graphics, 40(4):88:1-88:13, August 2021 (article)
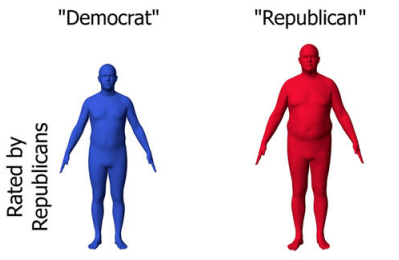
Red shape, blue shape: Political ideology influences the social perception of body shape
Quiros-Ramirez, M. A., Streuber, S., Black, M. J.
Humanities and Social Sciences Communications, 8, pages: 148, June 2021 (article)

Weight bias and linguistic body representation in anorexia nervosa: Findings from the BodyTalk project
(Top Cited Article 2021-2022)
Behrens, S. C., Meneguzzo, P., Favaro, A., Teufel, M., Skoda, E., Lindner, M., Walder, L., Quiros-Ramirez, A., Zipfel, S., Mohler, B., Black, M., Giel, K. E.
European Eating Disorders Review, 29(2):204-215, Wiley, March 2021 (article)

Analyzing the Direction of Emotional Influence in Nonverbal Dyadic Communication: A Facial-Expression Study
Shadaydeh, M., Mueller, L., Schneider, D., Thuemmel, M., Kessler, T., Denzler, J.
IEEE Access, 9, pages: 73780-73790, IEEE, 2021 (article)
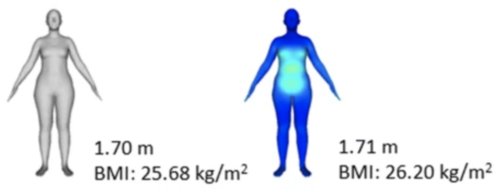
Body Image Disturbances and Weight Bias After Obesity Surgery: Semantic and Visual Evaluation in a Controlled Study, Findings from the BodyTalk Project
Meneguzzo, P., Behrens, S. C., Favaro, A., Tenconi, E., Vindigni, V., Teufel, M., Skoda, E., Lindner, M., Quiros-Ramirez, M. A., Mohler, B., Black, M., Zipfel, S., Giel, K. E., Pavan, C.
Obesity Surgery, 31(4):1625-1634, 2021 (article)
2020
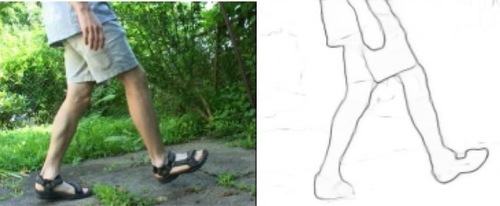
Occlusion Boundary: A Formal Definition & Its Detection via Deep Exploration of Context
Wang, C., Fu, H., Tao, D., Black, M. J.
IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(5):2641-2656, November 2020 (article)

3D Morphable Face Models - Past, Present and Future
Egger, B., Smith, W. A. P., Tewari, A., Wuhrer, S., Zollhoefer, M., Beeler, T., Bernard, F., Bolkart, T., Kortylewski, A., Romdhani, S., Theobalt, C., Blanz, V., Vetter, T.
ACM Transactions on Graphics, 39(5):157, October 2020 (article)
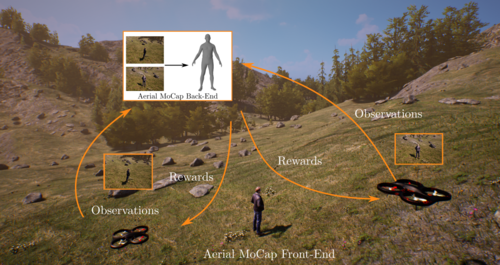
AirCapRL: Autonomous Aerial Human Motion Capture Using Deep Reinforcement Learning
Tallamraju, R., Saini, N., Bonetto, E., Pabst, M., Liu, Y. T., Black, M., Ahmad, A.
IEEE Robotics and Automation Letters, 5(4):6678-6685, IEEE, October 2020, Also accepted and presented in the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). (article)

Analysis of motor development within the first year of life: 3-D motion tracking without markers for early detection of developmental disorders
Parisi, C., Hesse, N., Tacke, U., Rocamora, S. P., Blaschek, A., Hadders-Algra, M., Black, M. J., Heinen, F., Müller-Felber, W., Schroeder, A. S.
Bundesgesundheitsblatt - Gesundheitsforschung - Gesundheitsschutz, 63(7):881–890, July 2020 (article)
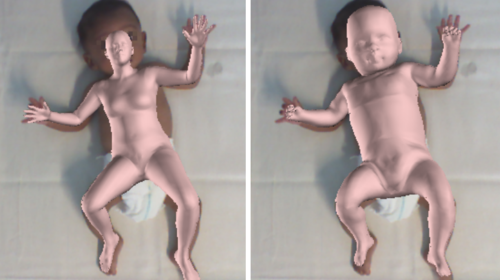
Learning and Tracking the 3D Body Shape of Freely Moving Infants from RGB-D sequences
Hesse, N., Pujades, S., Black, M., Arens, M., Hofmann, U., Schroeder, S.
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 42(10):2540-2551, 2020 (article)

General Movement Assessment from videos of computed 3D infant body models is equally effective compared to conventional RGB Video rating
Schroeder, S., Hesse, N., Weinberger, R., Tacke, U., Gerstl, L., Hilgendorff, A., Heinen, F., Arens, M., Bodensteiner, C., Dijkstra, L. J., Pujades, S., Black, M., Hadders-Algra, M.
Early Human Development, 144, pages: 104967, May 2020 (article)

Real Time Trajectory Prediction Using Deep Conditional Generative Models
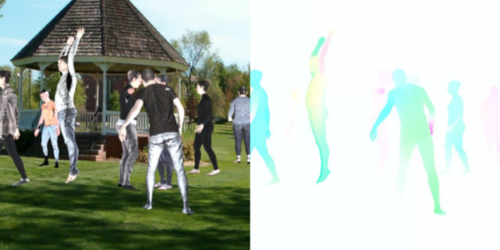
Learning Multi-Human Optical Flow
Ranjan, A., Hoffmann, D. T., Tzionas, D., Tang, S., Romero, J., Black, M. J.
International Journal of Computer Vision (IJCV), 128(4):873-890, April 2020 (article)
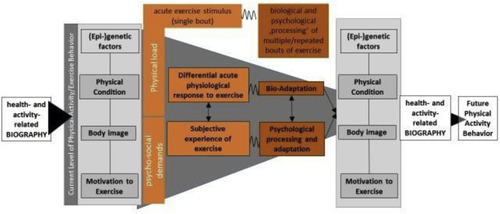
The iReAct study - A biopsychosocial analysis of the individual response to physical activity
Thiel, A., Sudeck, G., Gropper, H., Maturana, F. M., Schubert, T., Srismith, D., Widmann, M., Behrens, S., Martus, P., Munz, B., Giel, K., Zipfel, S., Niess, A. M.
Contemporary Clinical Trials Communications , 17, pages: 100508, March 2020 (article)

Influence of Physical Activity Interventions on Body Representation: A Systematic Review
Srismith, D., Wider, L., Wong, H. Y., Zipfel, S., Thiel, A., Giel, K. E., Behrens, S. C.
Frontiers in Psychiatry, 11, pages: 99, 2020 (article)
2019
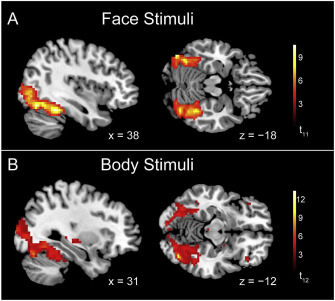
Decoding subcategories of human bodies from both body- and face-responsive cortical regions
Foster, C., Zhao, M., Romero, J., Black, M. J., Mohler, B. J., Bartels, A., Bülthoff, I.
NeuroImage, 202(15):116085, November 2019 (article)
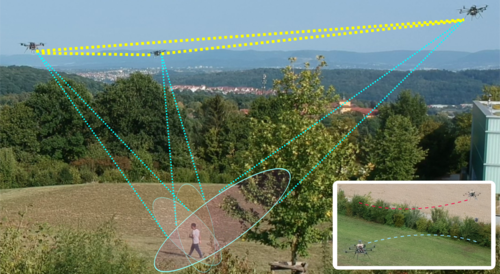
Active Perception based Formation Control for Multiple Aerial Vehicles
Tallamraju, R., Price, E., Ludwig, R., Karlapalem, K., Bülthoff, H. H., Black, M. J., Ahmad, A.
IEEE Robotics and Automation Letters, Robotics and Automation Letters, 4(4):4491-4498, IEEE, October 2019 (article)

Decoding the Viewpoint and Identity of Faces and Bodies
Foster, C., Zhao, M., Bolkart, T., Black, M., Bartels, A., Bülthoff, I.
Journal of Vision, 19(10): 54c, pages: 54-55, Arvo Journals, September 2019 (article)
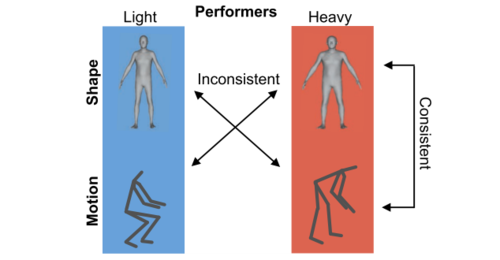
Perceptual Effects of Inconsistency in Human Animations
Kenny, S., Mahmood, N., Honda, C., Black, M. J., Troje, N. F.
ACM Trans. Appl. Percept., 16(1):2:1-2:18, February 2019 (article)

The Virtual Caliper: Rapid Creation of Metrically Accurate Avatars from 3D Measurements
Pujades, S., Mohler, B., Thaler, A., Tesch, J., Mahmood, N., Hesse, N., Bülthoff, H. H., Black, M. J.
IEEE Transactions on Visualization and Computer Graphics, 25(5):1887-1897, IEEE, 2019 (article)
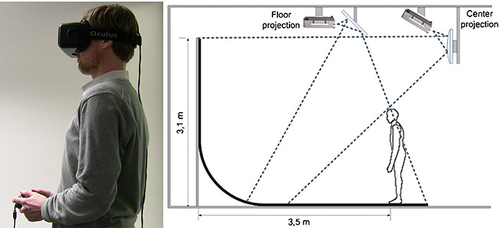
Self and Body Part Localization in Virtual Reality: Comparing a Headset and a Large-Screen Immersive Display
van der Veer, A. H., Longo, M. R., Alsmith, A. J. T., Wong, H. Y., Mohler, B. J.
Frontiers in Robotics and AI, 6(33), 2019 (article)
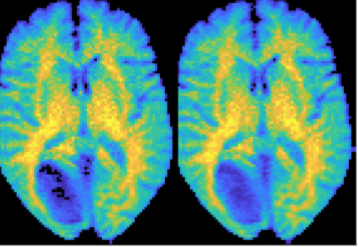
DeepCEST 3T: Robust MRI parameter determination and uncertainty quantification with neural networks—application to CEST imaging of the human brain at 3T
Glang, F., Deshmane, A., Prokudin, S., Martin, F., Herz, K., Lindig, T., Bender, B., Scheffler, K., Zaiss, M.
Magnetic Resonance in Medicine , 84(1):450-466, 2019 (article)
2018

Deep Inertial Poser: Learning to Reconstruct Human Pose from Sparse Inertial Measurements in Real Time
Huang, Y., Kaufmann, M., Aksan, E., Black, M. J., Hilliges, O., Pons-Moll, G.
ACM Transactions on Graphics, (Proc. SIGGRAPH Asia), 37, pages: 185:1-185:15, ACM, November 2018, Two first authors contributed equally (article)
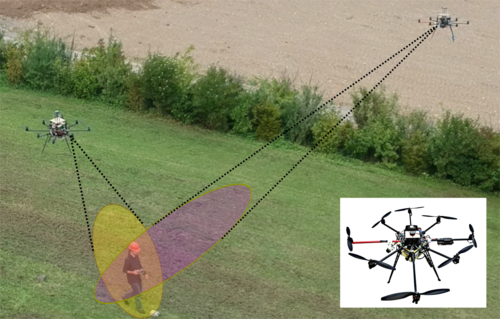
Deep Neural Network-based Cooperative Visual Tracking through Multiple Micro Aerial Vehicles
Price, E., Lawless, G., Ludwig, R., Martinovic, I., Buelthoff, H. H., Black, M. J., Ahmad, A.
IEEE Robotics and Automation Letters, Robotics and Automation Letters, 3(4):3193-3200, IEEE, October 2018, Also accepted and presented in the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). (article)
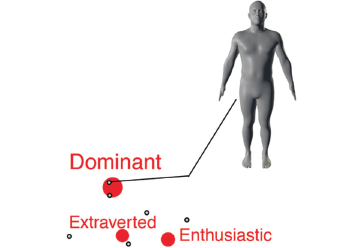
First Impressions of Personality Traits From Body Shapes
Hu, Y., Parde, C. J., Hill, M. Q., Mahmood, N., O’Toole, A. J.
Psychological Science, 29(12):1969-–1983, October 2018 (article)

Visual Perception and Evaluation of Photo-Realistic Self-Avatars From 3D Body Scans in Males and Females
Thaler, A., Piryankova, I., Stefanucci, J. K., Pujades, S., de la Rosa, S., Streuber, S., Romero, J., Black, M. J., Mohler, B. J.
Frontiers in ICT, 5, pages: 1-14, September 2018 (article)

Robust Physics-based Motion Retargeting with Realistic Body Shapes
Borno, M. A., Righetti, L., Black, M. J., Delp, S. L., Fiume, E., Romero, J.
Computer Graphics Forum, 37, pages: 6:1-12, July 2018 (article)
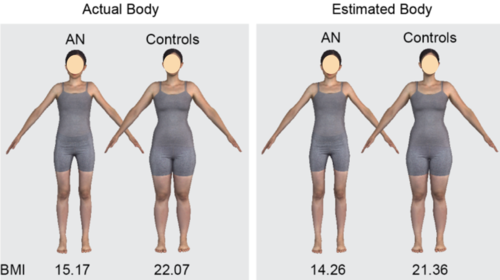
Assessing body image in anorexia nervosa using biometric self-avatars in virtual reality: Attitudinal components rather than visual body size estimation are distorted
Mölbert, S. C., Thaler, A., Mohler, B. J., Streuber, S., Romero, J., Black, M. J., Zipfel, S., Karnath, H., Giel, K. E.
Psychological Medicine, 48(4):642-653, March 2018 (article)

Body size estimation of self and others in females varying in BMI
Thaler, A., Geuss, M. N., Mölbert, S. C., Giel, K. E., Streuber, S., Romero, J., Black, M. J., Mohler, B. J.
PLoS ONE, 13(2), February 2018 (article)
Motion Segmentation & Multiple Object Tracking by Correlation Co-Clustering
Keuper, M., Tang, S., Andres, B., Brox, T., Schiele, B.
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018 (article)
Temporal Human Action Segmentation via Dynamic Clustering
Zhang, Y., Sun, H., Tang, S., Neumann, H.
arXiv preprint arXiv:1803.05790, 2018 (article)
2017

Learning a model of facial shape and expression from 4D scans
Li, T., Bolkart, T., Black, M. J., Li, H., Romero, J.
ACM Transactions on Graphics, 36(6):194:1-194:17, November 2017, Two first authors contributed equally (article)
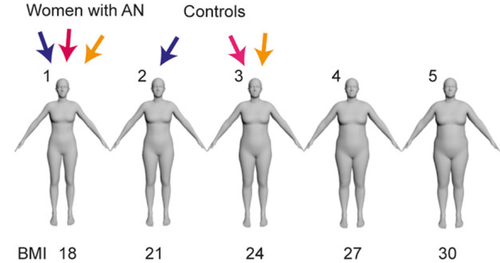
Investigating Body Image Disturbance in Anorexia Nervosa Using Novel Biometric Figure Rating Scales: A Pilot Study
Mölbert, S. C., Thaler, A., Streuber, S., Black, M. J., Karnath, H., Zipfel, S., Mohler, B., Giel, K. E.
European Eating Disorders Review, 25(6):607-612, November 2017 (article)